- Research
- Open access
- Published:
Lightning-fast and privacy-preserving outsourced computation in the cloud
Cybersecurity volume 3, Article number: 17 (2020)
Abstract
In this paper, we propose a framework for lightning-fast privacy-preserving outsourced computation framework in the cloud, which we refer to as LightCom. Using LightCom, a user can securely achieve the outsource data storage and fast, secure data processing in a single cloud server different from the existing multi-server outsourced computation model. Specifically, we first present a general secure computation framework for LightCom under the cloud server equipped with multiple Trusted Processing Units (TPUs), which face the side-channel attack. Under the LightCom, we design two specified fast processing toolkits, which allow the user to achieve the commonly-used secure integer computation and secure floating-point computation against the side-channel information leakage of TPUs, respectively. Furthermore, our LightCom can also guarantee access pattern protection during the data processing and achieve private user information retrieve after the computation. We prove that the proposed LightCom can successfully achieve the goal of single cloud outsourced data processing to avoid the extra computation server and trusted computation server, and demonstrate the utility and the efficiency of LightCom using simulations.
Introduction
THE internet of things (IoT), embedded with electronics, Internet connectivity, and other forms of hardware (such as sensors), is a computing concept that describes the idea of everyday physical objects being connected to the internet and being able to identify themselves to other devices. With large numbers of IoT devices, a colossal amount of data is generated for usage. According to IDCFootnote 1, the connected IoT devices will reach 80 billion in 2025, and help to generate 180 trillion gigabytes of new data that year. A quarter of the data will create in real-time, and 95% is to come from IoT real-time data. With such a large volume, real-time data are generated; it is impossible for the resource-limited IoT devices to store and do the data analytics in time. Cloud computing (Ali et al. 2015; Wei et al. 2014; Wazid et al. 2020; Challa et al. 2020), equipped the almost unlimited power of storage and computing provides the diversity of services on demand, such as storage, databases, networking, software, analytics, intelligence. With the help of cloud computing, 49 percent of data will be stored in public cloud environments by 2025Footnote 2. Unsurprisingly, the massive volume of data generated by IoT devices is outsourced to the cloud for long-term storage and achieve real-time online processing.
Despite the advantages provided by IoT-cloud data outsourcing architecture, the individual IoT users hesitate to use the system for data storage and processing without any protection method. On the Internet of Medical Things example (Dimitrov 2016), patients wearable mHealth devices that always equipped with biometric measurement sensors (such as heart rate, perspiration levels, oxygen levels) to record the physical sign of the patient. The hospital can use clients PHI decision-making model to automatically check a patients health status. According to a new report by Grand View Research, The global IoT in healthcare market size is projected to reach USD 534.3 billion by 2025 expanding at a Compound Annual Growth Rate (CAGR) 19.9% over the forecast periodFootnote 3. If no protection method is adopted, patients physical signs can be capture by an adversary. Moreover, the hospital model can be got by other third-party companies to make a profit. Use the traditional encryption technique can protect the data from leakage; however, the ciphertext lost the original meaning of the plaintext, which cannot do any computations.
Protecting the data and achieve the secure outsource computation simultaneously is an eye-catching field to solve the above problems. Currently, there are typically two aspects of techniques to achieve secure outsourced computation: theoretical cryptography solution and system security solution. For the cryptography point of view, homomorphic encryption (Naehrig et al. 2011) is considered as a super-excellent solution for the outsourced computation, which allows the third-party to perform the computation on the encrypted data without revealing the content of the plaintext. Fully homomorphic encryption (Van Dijk et al. 2010) can achieve arbitrary computation on the plaintext corresponding to the complex operations on the ciphertext. However, the computation overhead is still tremendous, which is not fit for the piratical usage (e.g., it requires 29.5 s to run secure integer multiplication computation with a standard PC (Liu et al. 2018b)). Semi-homomorphic encryption (Bendlin et al. 2011; Farokhi et al. 2016; Ma et al. 2020) only supports one type of homomorphic (e.g., additive homomorphic), can achieve complex data computation on the encrypted data with the help of other honest-but-curious servers. However, the extra computation server will increase the possibility of information leakage. Recently, for the industrial community, trusted execution environment (TEE, such as Intel\(^{\circledR }\) Software Guard Extensions (SGX)Footnote 4 and ARM TrustZoneFootnote 5) is developed to achieve the secure computation which allows user-level or operating system code to define private regions of memory, also called enclaves. The data in the enclave are protected and unable to be either read or saved by any process outside the enclave itself. The performance of the TEE is equivalent to the plaintext computation overhead. Unfortunately, TEE easily faces the side-channel attack, and the information inside the enclave can be leaked to the adversaryFootnote 6Footnote 7. Thus, a fascinating problem appears for creating a system to balance the usage of practical outsourced computation system and eliminate the extra information leakage risk: how can a single cloud securely perform the arbitrary outsourced computation without the help of extra third-party computation server or trusted authority, which interactions between the user and the cloud kept to a minimum.
In this paper, we seek to address the challenges as mentioned above by presenting a framework for lightning-fast and privacy-preserving outsourced computation Framework in a Cloud (LightCom). We regard the contributions of this paper to be six-fold, namely:
-
Secure Data Outsourced Storage. The LightCom allows each user to outsource his/her data to a cloud data center for secure storage without compromising the privacy of his/her data to the other unauthorized storage.
-
Lightning-fast and Secure Data Processing in Single Cloud. The LightCom can allow in a single cloud equipped with multiple Trusted Processing Units (TPUs), which provides a TEE to achieve the user-centric outsourced computation on the user’s encrypted data. Moreover, the data in untrusted outside storage are secure against chosen-ciphertext attacks for the long-term, while data insider TPUs can be protected against side-channel attacks.
-
Outsourced Computation Primitive Combinable. Currently, the outsourced computation methods focus on a special computation task, such as outsourced exponential computation. Different specific outsourced tasks are constructed with different crypto preliminary. Thus, the previous computation result cannot be directly used for the input of the next computation. Our LightCom can directly solve the problem with a uniform design method which can achieve computation combinable.
-
No Trusted Authority Involved. In most of the existing cryptosystems, trusted authority is fully trusted, which is an essential party in charge of distributing the public/private keys for all the other parties in the system. Our LightCom does not involve an extra fully trusted party in the system, which makes the system more efficient and practical.
-
Dynamic Key/Ciphertext Shares Update. To reduce the user’s private key and data leakage risk during the processing, we randomly split the key and data into different shares which are processed in different TPUs, cooperatively. To avoid long-term shares leaking for recovering the original secrets, our LightCom allows TPUs updating user’s “old” data/private-key shares into the “new” shares on-the-fly dynamically without the participation of the data user.
-
High User Experience. Most existing privacy-preserving computation technique requires a user to perform different pre-processing technique according to the function type before data outsourcing. The LightCom does not need the data owner to perform any pre-processing procedure - only needs to encrypt and outsource the data to the cloud for storage. Thus, interactions between the user and the cloud kept to a minimum - send the encrypted data to the cloud, and received outsourced computed results in a single round.
Motivation and Technique Overview. As the sensitive information contained inside TPU can be attacked, our primary motivation of the LightCom framework is to achieve secure computation in a single cloud without the help of an additional party. Also, as most of the devices are mobile devices with battery restriction, we need to guarantee users experience to make sure that the interactions between the user and the cloud kept to one round. The design idea of LightCom is to let the data store in the outside storage, and achieve privacy-preserving computation insider TPU. The main challenges are how to achieve both practical secure data storage and outsourced data processing against side-channel attacks, simultaneously.
To solve the secure data storage challenge, we use a new Paillier Cryptosystem Distributed Decryption (PCDD), which can achieve semantic secure data storage. To prevent information leakage inside TPU, our LightCom uses one-time pad by adding some random numbers on the plaintext of the PCDD ciphertext. Even the “padded” ciphertext for the TPU enclave for decryption and process, the attacker still cannot get the original message of the plaintext. To achieve ciphertext decryption, our LightCom uses multiple TPUs, and each TPU only stores a share of the private key to prevent the user’s key leakage risk. Even some partial private key/data shares may leak to the adversary; our framework can successfully update these shares dynamically inside the TPU to make the leaked shares useless. More importantly, all the secure execution environment (called TPU enclaves) in TPUs are dynamically building and release for the secure computation in our LightCom framework, which can further decrease the information leak risk in the enclave.
Applications with LightCom. The LightCom is a fundamental secure data computation framework which can be used for the following four types of applications – see Fig. 1.

LightCom with the Applications
1. Artificial Intelligence (AI) System. AI is the simulation of human intelligence processes by machines, especially computer systems, which can be used in expert systems, natural language processing (NLP), speech recognition and machine vision. However, in most of the AI applications, the data for AI model training and decision are sensitive which need to be protected before sending into the AI model. Also, the AI model is considered as the core asset of the company which requires a staggering cost for training. With the help of LightCom, both data and AI models can be protected, and all the basic secure operations can be used for building the secure AI system without leaking any information about the model parameters.
2. E-Healthcare System. E-healthcare is a field in the intersection of public health, and medical informatics, referring to health services and information delivered or enhanced through the Internet and related technologies. An Electronic Health Record (EHR) is considered as the key to the e-healthcare system which provides real-time, patient-centric records that make information available instantly to the users. To ensure the privacy of the record, some researchers provide secure techniques to encrypt the EHR (Xu et al. 2020a, b; 2018). However, encrypted EHR cannot do any operations without decryption. Thanks to the LightCom, the third-party company can use the encrypted EHR in the e-healthcare system for practical secure data analytics without any information leakage. The patient can use his/her own private key to decrypt and get the real-time analytic e-healthcare result.
3. Connected and Automated Vehicles (CAV). The transportation system is rapidly evolving with new CAV technologies that integrate CAVs with other vehicles and roadside infrastructure in a cyber-physical system (CPS). For the vehicle to be truly capable of driving without user control, an extensive amount of training must be initially undertaken for the AI system to make the right decisions in any imaginable traffic situation. However, the compromised vehicle can capture data packet information, thus acquiring sensitive and confidential data. Cryptography-based solutions include encryption that can be used to detect eavesdropping and secure vehicle privacy. However, the automated vehicle cannot make any operations on the encrypted training data packets. In order to train the self-divining model in a privacy-preserving way, the LightCom can be used for constructing the model without the training data leakage.
4. Social Network (SN). A social network is a social structure made up of a set of social actors (such as individuals or organizations), sets of dyadic ties, and other social interactions between actors. Social network user’s private information including messages, invitations, photos, are often the venues for other adversaries to gain access. However, these data are valuable for the service provider that can be extracted useful knowledge from them. The traditional encryption technologies can successfully deal with the user’s private information, but make the social media data unusable. With the LightCom, the service provider can achieve secure data analytics without getting any social actors’ private information.
Preliminary
Notations
Throughout the paper, we use ∥x∥ to denote bit-length of x, while \({\mathcal {L}}(x)\) denotes the number of element in x. Moreover, we use pka and ska to denote the public and private keys of a Request User (RU) a, \(sk_{a}^{(1)}, sk_{a}^{(2)}\) to denote the partial private keys that form ska, \([\!\![x]\!\!]_{pk_{a}}\) to denote the encrypted data of x using pka in public-key cryptosystem. For simplicity, if all ciphertexts belong to a specific RU, say a, we simply use [ [x] ] instead of \([\!\![x]\!\!]_{pk_{a}}\). We use notion 〈m〉 to denote the data share of m, i.e., each party i\((i = 1,\cdots, {\mathcal {P}})\) holds mi, such that \(\sum _{i=1}^{{\mathcal {P}}}m_{i} = m\).
Additive secret sharing scheme (ASS)
Give \(m\in \mathbb {G}\) (\(\mathbb {G}\) is a finite abelian group under addition), the additive secret sharing scheme (a.k.a. \(\mathcal {P}\)-out-of-\(\mathcal {P}\) secret sharing scheme) can be classified into the following two algorithms – Data Share Algorithm (Share) and Data Recovery Algorithm (Rec):
Share(m): Randomly generate \(X_{1},\cdots, X_{{\mathcal {P}}-1} \in \mathbb {G}\), the algorithm computes \(X_{\mathcal {P}} = m -(X_{1}+\cdots +X_{{\mathcal {P}}-1})\), and outputs \(X_{1},\cdots, X_{{\mathcal {P}}}.\)
\(\texttt {Rec}(X_{1},\cdots,X_{\mathcal {P}}):\) With the shares \(X_{1},\cdots,X_{\mathcal {P}}\), the algorithm can recover the message m by computing with \(m = X_{1}+\cdots +X_{\mathcal {P}}\) under group \(\mathbb {G}\).
Additive homomorphic encryption scheme
To reduce the communication cost of the LightCom, we used an Additive Homomorphic Encryption (AHE) scheme as the basis. Specifically, we use one of the AHE support threshold decryption called Paillier Cryptosystem Distributed Decryption (PCDD) in our previous work which contains six algorithms called Key Generation (KeyGen), Data Encryption (Enc), Data Decryption (Dec), Private Key Splitting (KeyS), Partially decryption (PDec), Threshold decryption (TDec). The plaintext belongs to \(\mathbb {Z}_{N}\) and the ciphertext belongs to \(\mathbb {Z}_{N^{2}}\). The construction of the above algorithms can be found in Supplementary Materials Section C. Here, we introduce the two properties of the PCDD as follows: 1) Additive Homomorphism: Given ciphertexts [ [m1] ] and [ [m2] ] under a same public key pk, the additive homomorphism can be computed by ciphertext multiplication, i.e., compute [ [m1] ]·[ [m2] ]=[ [m1+m2] ]. 2) Scalar-multiplicative Homomorphism: Given ciphertext [ [m] ] and a constant number \(c \in \mathbb {Z}_{N}\), it has ([ [m] ])c=[ [cm] ].
With the two properties given above, we show that our PCDD have the polynomial homomorphism property, i.e., given [ [x1] ],⋯,[ [xn] ] and a1,⋯,an, it has
Mathematical function computation
In this section, we define the function which is used for data processing in our LightCom.
Definition 1
(Deterministic Multiple-output Multivariable Functions) Let \(D = \{(x_{1},\cdots, x_{v}) : x_{i} \in \mathbb {G} \}\) be a subset of \(\mathbb {G}^{v}.\) We define the deterministic multiple-output multivariable function as follows: (I) A multiple-output multivariable function \(\mathcal {F}\) of v variables is a rule which assigns each ordered vector (x1,⋯,xv) in D to a unique vector denoted (y1,⋯,yw), denote \( (y_{1},\cdots, y_{w}) \leftarrow {\mathcal {F}}(x_{1},\cdots,x_{v})\). (II) The set D is called the domain of \(\mathcal {F}\). (III) The set \({\{\mathcal {F}}(x_{1},\cdots,x_{v})| (x_{1},\cdots, x_{v}) \in D\}\) is called the range of \(\mathcal {F}\).
Note that the deterministic multiple-output multivariable function is the general case of the deterministic multiple-output single-variable function (v=1), deterministic single-output multivariable function (w=1), and deterministic single-output single variable function (v=1,w=1). As all the functions used in our paper can be successfully executed by a polynomial deterministic Turing machine (See Supplementary materials Section A), we omit the word “deterministic” in the rest of the paper.
System model & privacy requirement
In this section, we formalize the LightCom system model, and define the attack model.
System model
In our LightCom system, we mainly focus on how the cloud server responds to a user request on outsourced computation in a privacy-preserving manner. The system comprises Request User (RU) and a Cloud with Untrusted Storage (UnS) and Trusted Processing Units (TPUs) - see Fig. 2.
-
A RU generates his/her public key, private key shares, and data shares. After that, the RU can securely outsource the public key and private/data shares to the cloud’s UnS for secure storage (See ①). Moreover, the RU can also request a cloud to perform some secure outsourced computations on the outsourced data and securely retrieve the final encrypted results (See ⑤).
Fig. 2 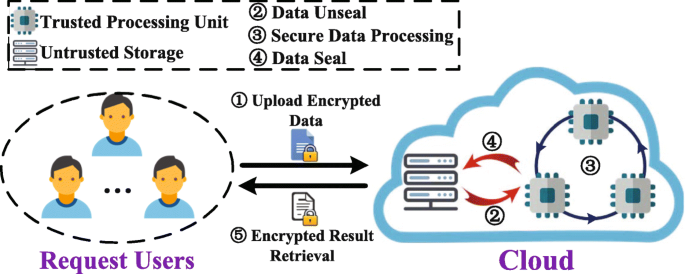
System model under consideration
-
A UnS of the cloud has ‘unlimited’ data storage space to store and manage data outsourced from the registered RU. Also, the UnS stores all the intermediate and final results for the RU in encrypted form.
-
The TPUs of the cloud provides online computation ability for each RUs. Each TPU provides isolation secure computing environment for individual RU and can load RU’s data shares from UnS (See ②), perform certain calculations over the data shares (See ③), and then securely seal the data shares in UnS for storage (See ④)Footnote 8. Note that one TPU cannot load other TPU’s sealed data, which are stored in UnS.

Attack model
In our attack model, the cloud is curious-but-honest party, which strictly follow the protocol, but are also interested in learning data belonged to the RUs. The UnS inside the cloud is transparency to both the cloud and the outsider passive attackers. Every TPU can provide a secure execution environment (a.k.a., TPU enclave) for a RU, which is secure against the other RU, the cloud, and outsider passive attackers. The inside non-challenge RUs and outside attackers can also be interested to learn challenge RU’s data. Therefore, we introduce three active adversaries \({\mathcal {A}}^{*}_{1}, {\mathcal {A}}^{*}_{2}, {\mathcal {A}}^{*}_{3}, \) which can simulate the malicious actions corresponding to the outside attackers, non-challenge RUs, UnS, respectively. The goal of these adversaries is to get the challenge RU’s plaintext or try to let the challenge RU get wrong computation result with the following capabilities:
1) \({\mathcal {A}}^{*}_{1}\) acts as the outside attacker that may eavesdrop on all communication links and CP’s UnS, and try to decrypt the challenge RU’s encrypted data. 2) \({\mathcal {A}}^{*}_{2}\) may compromise RUs, except for the challenge RU, to get access to their decryption capabilities, and try to guess all plaintexts belonging to the challenge RU. 3) \({\mathcal {A}}^{*}_{3}\) may compromise the TPU to guess plaintext values of all data shares sent from the UnS by executing an interactive protocol. Noting that the above adversaries \({\mathcal {A}}^{*}_{1}, {\mathcal {A}}^{*}_{2}, {\mathcal {A}}^{*}_{3}\) are restricted from compromising (i) all the TPUs concurrentlyFootnote 9, and (ii) the challenge RU.
Basic privacy preserving computation protocols
In this section, we introduce our general design method of the mathematical function for LightCom. Moreover, the dynamic private/data share update without the participation of the DO are also introduced.
The LightCom design method for the single functions
Our LightCom achieves the user data’s privacy during the efficiency in the outsourced cloud with three-dimensional protection: 1) secure storing in the untrusted cloud storage; 2) secure processing in TPUs against side-channel attack; 3) efficient and dynamic outsourced key and data shares updating. Specifically, to outsource the data to the cloud, the RU first initializes the system, uses the RU’s public key to encrypt the data, and outsources these encryptions and the system parameters to UnS for storage. To achieve the second-dimensional protection, our LightCom uses the data sharing-based secure computation method between TPUs, which can resist the side-channel attacks even the PPCD ciphertexts are decrypted. After finishing the processing, the data are sent back to UnS for further processing to complete the corresponding functionality defined in the program, and the enclaves in TPUs are released. Moreover, to tackle the leaked private key and data shares, all the TPUs can jointly update these shares without the help of RU. Thus, the LightCom can classify into the following four phases.
1) System Initialize Phase: Firstly, the RU generates a public key pk and private key is sk of appropriate public key crypto-system, and then splits the private key sk into \({\mathcal {P}}\) shares ski\((i = 1,\cdots, {\mathcal {P}})\) with the Share algorithm. After that, for each TPU i in the cloud, it initials an enclave i, builds a secure channel, and uploads the ski to the enclave i securely. Finally, the TPU i uses the data sealing to securely stored the pk, ski in to UnS.
2) Data Upload Phase: In the phase, the RU randomly separates the data \(x_{j,1},\cdots,x_{j,{\mathcal {P}}} \in \mathbb {G}\), such that \(x_{j,1}+ \cdots +x_{j,{\mathcal {P}}} = x_{j} \) for j=1,⋯,v. Then, the TPU i\((i = 1,\cdots, {\mathcal {P}})\) creates the enclave i. After that, the RU defines the program \({\mathcal {C}}_{i}\) for some specific computation function, builds a secure channel with TPU enclave i, remotely loads \(x_{1,i},\cdots,x_{v,i}, {\mathcal {C}}_{i}\) into the enclave i, and securely seals \( x_{1,i},\cdots,x_{v, i}, {\mathcal {C}}_{i} \) in the UnS. After that, TPU i releases the enclave i.
3) Secure Computation Phase: The goal of the phase is to achieve the secure computation among the TPUs according to the user-defined program \({\mathcal {C}}_{i}\). Thus, it works as follows:
-
(3-I) Each TPU i generates an enclave i. After that, all the TPUs build a secure channel with each other. Load sealed data \( x_{1,i},\cdots,x_{v,i}, pk, sk_{i}, {\mathcal {C}}_{i}\) to enclave i from UnS, and denote them as Si.
-
(3-II) TPUs jointly compute \((y_{1,1},\cdots,y_{w,1}:\cdots : y_{1,{\mathcal {P}}},\cdots,y_{w,{\mathcal {P}}}) \leftarrow \texttt {GenCpt} (S_{1}:\cdots :S_{\mathcal {P}})\) according to the user-defined program \({\mathcal {C}}_{1},\cdots,{\mathcal {C}}_{\mathcal {P}}\)Footnote 10.
-
(3-III) All the TPUs jointly update the private key shares and data shares dynamically.
After the above computation, the TPU i seals y1,i,⋯,yw,i into the UnS, and releases the enclave.
4) Data Retrieve Phase: If the RU needs to retrieve the computation results from the cloud, the TPU i creates an enclave i, opens the sealed data y1,i,⋯,yw,i, builds a secure channel with the RU, and sends the data shares back to RU. Once all the shares are sends to RU, the RU computes \(y_{j} = \sum _{i=1}^{\mathcal {P}} y_{j,i}\) for j=1,⋯,w.
The LightCom Design for Combination of the Functions
Our LightCom can support for single data outsourced with multiple function operations. The procedure is as follows:
1) System Initialize Phase: Same to the LightCom with single function in “The LightCom design method for the single functions” section.
2) Data Upload Phase: After the system initialize phase, the RU defines the program \({\mathcal {C}}_{i,t}\) for TPU i\((i = 1,\cdots, {\mathcal {P}})\) with function computation step t (t=1,⋯,ζ) and randomly separates the data \(x_{j,1,1},\cdots,x_{j,1,{\mathcal {P}}}\), such that \(x_{j,1,1}+ \cdots +x_{j,1,{\mathcal {P}}} = x_{j}\) for j=1,⋯,vFootnote 11. After that, the RU builds a secure channel with TPU enclave i, remotely loads \({\mathcal {C}}_{1,i},\cdots,{\mathcal {C}}_{\zeta,i}\), x1,1,i,⋯,xv,1,i into the enclave i, and securely seals these data in the UnS. After that, TPU i release enclaves i for all the \(i = 1,\cdots, {\mathcal {P}}\).
3) Secure Computation Phase: The goal of the phase is to achieve the secure computation among the TPUs according to the user-defined program \({\mathcal {C}}_{t,i}\) for function t (t=1,⋯,ζ). Thus, for each step t, the phase works as follows:
-
(3-I) Each TPU i generates an enclave i. After that, all the TPUs build a secure channel with each other. Load sealed data x1,t,i,⋯,xv,t,i,pk,ski,\({\mathcal {C}}_{1,i},\cdots,{\mathcal {C}}_{\zeta,i}\) to enclave i from UnS, and put them in a set \({\mathcal {E}}_{t,i}\).
-
(3-II) TPUs jointly compute \((y_{1,t,1},\cdots,y_{w,t,1}:\cdots : y_{1,t,n},\cdots,y_{w,t,{\mathcal {P}}}) \leftarrow \texttt {GenCpt} ({\mathcal {E}}_{t,i}:\cdots :{\mathcal {E}}_{t,i})\), according to the user-defined program \({\mathcal {C}}_{1,i},\cdots,{\mathcal {C}}_{\zeta,i}\).
-
(3-III) All the TPUs jointly update the private key and data shares. If t=ζ, the TPU i seals y1,ζ,i,⋯,yw,ζ,i into the UnS, release the enclave. Otherwise, move to (3-IV) for further computation.
-
(3-IV) Select x1,t+1,i,⋯,xv,t+1,i from the y1,t,i,⋯,yw,t,i for TPU i. Then, the TPU i seals x1,t+1,i,⋯,xv,t+1,i into the UnS, release the enclave, and move to (3-I) for next step computation.
After the t step is finished, the TPU i seals the set \({\mathcal {E}}_{j}\) into the UnS, and releases the corresponding enclave.
4) Data Retrieve Phase: After the computation, TPU i new an enclave i, opens the sealed data y1,ζ,i,⋯,yw,ζ,i, builds a secure channel with the RU, and sends these data back to the RU. Once all the TPU’s data are sent, the RU computes the result \(y_{j,\zeta } = \sum _{i=1}^{\mathcal {P}} y_{j,\zeta,i}\) for step ζ (j=1,⋯,w) to get the final results.
General secure function computation algorithm (GenCpt)
As the key component of the LightCom, the General Secure Function Computation Algorithm (GenCpt) are proposed to achieve the secure deterministic multiple-output multivariable function \(\mathcal {F}\) computation which is introduced in definition 1. Assume TPU i\((i = 1,\cdots, {\mathcal {P}})\) holds x1,i,⋯,xv,i, GenCpt can securely output y1,i,⋯,yw,i for each TPU i, such that \((y_{1},\cdots, y_{w}) \leftarrow {\mathcal {F}}(x_{1},\cdots,x_{v})\), where \(x_{j,1}+\cdots + x_{j,{\mathcal {P}}} = x_{j}\) and \(y_{k,1}+\cdots + y_{k, {\mathcal {P}}} = y_{k}\) for j=1,⋯,v;k=1,⋯,w. The GenCpt can be classified into offline/online stages and constructed as follows:
Offline Stage: Each TPU i (\(i = 1,\cdots, {\mathcal {P}}\)) creates an enclave i, loads the sealed keys pk,ski and program \({\mathcal {C}}_{i}\) into the enclave from the UnS, builds a secure channel with the other TPUsFootnote 12. With the help of homomorphic cryptosystem, all the TPUs can collaboratively generate the shares of random numbers and put them into a set \({\mathcal {R}}_{i}\). Note the shares in set \({\mathcal {R}}_{i}\) cannot be known by all the other TPUs during the generation. After the above computation, each TPU i seals the \({\mathcal {R}}_{i}\) into the UnS, respectively.
Online StageFootnote 13 For each TPU i (\(i = 1,\cdots, {\mathcal {P}}\)), loads the sealed random numbers set \({\mathcal {R}}_{i}\) from offline stage into the enclave i. All the TPUs cooperatively compute and output the results
where fi is the combination of +,× for \(\mathbb {Z}_{N}\) and ⊕,∧ for \(\mathbb {Z}_{2}\) with specific functionality according to the program \({\mathcal {C}}_{i}\).
Private key share dynamic update
The private key shares are more sensitive and vulnerable, as the adversary can use the private key to decrypt the RU’s data in the untrusted storage if the side-channel attack leaks all shares of the private key. Thus, we should frequently update the key shares in the TPU enclave. The intuitive idea is to let the RU choose a new private key, separate the new private key into different key shares, update these key shares in the different individual enclaves, and update all the ciphertext with the new key. However, the above strategy has the main drawback: the RU has to be involved in the private/public key update phase, which brings extra computation and communication costs. Thus, in this case, the RU needs to frequently generate and update the public/private keys, impractical. Therefore, we bring the idea of proactive secret sharing into the LightCom: keeps the public/private key unchanged, the TPU will periodicity refresh the key shares without the participation of the RU. Mathematically, to renew the shares at period t (t=0,1,2,⋯), we need to update the shares such that \( \sum ^{\mathcal {P}}_{i=1} sk_{i}^{(t+1)}= \sum ^{\mathcal {P}}_{i=1} sk_{i}^{(t)} + \sum ^{\mathcal {P}}_{i=1} \sum ^{\mathcal {P}}_{j=1} \delta ^{(t)}_{i,j} \), where \( \sum _{j=1}^{{\mathcal {P}}} \delta _{i,j} =0 \), \(\sum _{i=1}^{{\mathcal {P}}} sk^{(0)}_{i} = sk \) and \(sk^{(0)}_{i}= sk_{i}\) for \(i = 1,\cdots, {\mathcal {P}}\) (See Fig. 3 for example of private key update procedure with \({\mathcal {P}}=3\)). The special construction is as follows:

Key Shares Update (example of \({\mathcal {P}} =3 \))
1) Each TPU \(i (i = 1,\cdots, {\mathcal {P}})\) creates an enclave i. After that, TPU i the builds a secure channel with TPU j’s enclave \( (j = 1,\cdots, {\mathcal {P}}; j \neq i)\).
2) TPU i picks random numbers \(\delta _{i,1},\cdots,\delta _{i,{\mathcal {P}}} \in \mathbb {G}\) such that \(\delta _{i,1}+\cdots +\delta _{i, {\mathcal {P}}} = 0\) under the group \(\mathbb {G}\), and then sends δi,j to TPU enclave j.
3) After received δj,i, TPU i computes the new shares \(sk^{(t+1)}_{i} \leftarrow sk^{(t)}_{i} + \delta ^{(t)}_{1,i}+ \delta ^{(t)}_{2,i} + \cdots +\delta ^{(t)}_{{\mathcal {P}},i} \in \mathbb {G}\). After that, TPU i erases all the variables which it used, except for its current secret key \(sk^{(t+1)}_{i} \).
Data Shares Dynamic Update
As data shares need to load to TPU for processing, the shares can be leaked to the adversary by side-channel attack, and reconstruct the RU’s original data. Thus, we also need to dynamically update data shares \(x^{(t)}_{1},\cdots, x^{(t)}_{\mathcal {P}}\) at period t (t=0,1,2,⋯), such that \( \sum ^{\mathcal {P}}_{i=1} x_{i}^{(t+1)}= \sum ^{\mathcal {P}}_{i=1} x_{i}^{(t)} + \sum ^{\mathcal {P}}_{i=1} \sum ^{\mathcal {P}}_{j=1} \delta _{i,j}\), where \(\sum ^{\mathcal {P}}_{i=1} x^{(0)}_{i} = x\), \(x^{(0)}_{i}= x_{i}\), and \( \sum ^{\mathcal {P}}_{j=1} \delta _{i,j} =0\) for \(i = 1,\cdots, {\mathcal {P}}\). The construction is same to the private key share update method in “Private key share dynamic update” section.
TPU-based basic data shares operations
In this section, we introduce some basic TPU-based data shares operations, which can be used as LightCom.
Data domain and storage format
Here, we introduce three the data group domain for LightCom: \(\mathbb {Z}_{N} = \{0, 1, \cdots,N-1\}\), \(\mathbb {D}_{N} = \{-\lfloor \frac {N}{2}\rfloor, \cdots,0,\cdots, \lfloor \frac {N}{2}\rfloor)\), and \(\mathbb {Z}_{2} = \{0,1\}\). As we use PCDD for offline processing and its plaintext domain is \(\mathbb {Z}_{N}\), we define the operation ⌈x⌋N which transforms data x from group \(\mathbb {Z}_{N}\) into the group \(\mathbb {D}_{N}\), i.e.,
Moreover, the data ⌈x⌋N in group \(\mathbb {D}_{N}\) can be directly transformed into group \(\mathbb {Z}_{N}\) with x=⌈x⌋N mod N. It can be easily verified that group \(\mathbb {D}_{N}\) and \(\mathbb {Z}_{N}\) are isomorphism.
To guarantee the security of secret sharing, two types of data shares are used in the LightCom, called integer share (belonged to \(\mathbb {Z}_{N}\)) and binary share (belonged to \(\mathbb {Z}_{2}\)). For the integer share separation, RU only needs to execute Share(m) described in “Additive secret sharing scheme (ASS)” section, such that \(m = m_{1}+\cdots +m_{ {\mathcal {P}}}\), where \(m, m_{1},\cdots,m_{{\mathcal {P}}} \in \mathbb {D}_{N}\). For the binary shares, RU executes \(\texttt {Share}(\mathfrak {m})\), such that \(\mathfrak {m} = \mathfrak {m}_{1}+\cdots + \mathfrak {m}_{{\mathcal {P}}} \), where \(\mathfrak {m}, \mathfrak {m}_{1},\cdots, \mathfrak {m}_{{\mathcal {P}}} \in \mathbb {Z}_{2}.\) After that, RU securely sends integer share mi or binary shares \(\mathfrak {m}_{i}\) to TPU i, and seals to UnS for securely storage.
System initial and key distribution
The LightCom system should be initialized before achieving the secure computation. Firstly, the RU executes KeyGen algorithm, and outputs public key pk=(N,g) and private key sk=θ. Then, the system uses KeyS to split key θ into \(\mathcal {P}\) shares ski=θi\((i = 1,\cdots, { {\mathcal {P}}})\). After that, for each TPU i in the cloud, it initials an enclave i, builds a secure channel, and uploads the ski to the enclave i securely. Beside, the RU’s PCDD public key pk and program \({\mathcal {C}}_{i}\) for the specific function \(\mathcal {F}\) are needed to securely send to TPU i\((i = 1,\cdots, { {\mathcal {P}}})\). Finally, the TPU i securely seals the data pk, ski, \({\mathcal {C}}_{i}\) into UnS. As all the parameters need to load to the TPU enclaves along with the data shares according the specific functionality, we will not specially describe it in the rest of the section.
Secure distributed decryption algorithm (SDD)
Before executing the TPU-based operation, we first construct the algorithm called Secure Distributed Decryption (SDD), which allows all the TPUs to decrypt PCDD’s ciphertext. Mathematically, if enclave in TPU χ contains the encryption [ [x] ], the goal of SDD is to output x, which contains the following steps: 1) The TPU enclave χ establishes a secure channel with the other TPU enclave i(i≠χ). Then, enclave χ sends [ [x] ] to all the other enclave i. 2) Once received [ [x] ], the TPU i uses PDec to get CTi, and securely sends CTi to enclave χ. 3) Finally, the TPU χ securely uses CTχ with TDec algorithm to get x.
Secure TPU-based data seal & UnSeal
As TPU enclaves only provide an isolated computing environment during the secure processing, the data in the TPU enclave needs to seal to UnS for long-term storage. Thus, we propose two algorithms called Seal and UnSeal to achieve.
Seal(xi): The TPU i encrypts the data share x into [ [xi] ], then uses hash function \(H: \{0,1\}^{*} \rightarrow \mathbb {Z}_{N}\) with input the [ [xi] ] associated with TPU t-time period private key share \(sk^{(t)}_{i}\) to compute \(S_{t,i} \leftarrow H([\!\![x_{i}]\!\!] ||sk^{(t)}_{i}||ID_{i}||t)\), where IDi is the transaction identity for [ [xi] ]. Then, TPU i sends [ [xi] ] with St,i to UnS for storage.
UnSeal([ [x] ],St,i): The TPU i loads [ [xi] ] with St,i to the enclave i, and computes \(H([\!\![x]\!\!] ||sk^{(t)}_{i}||ID_{i}||t)\) to test whether the result is equal to St,i. If the equation does not holds, the algorithm stops and outputs ⊥. Otherwise, the TPU i uses SDD to get the share xi.
Random shares generation
The secret sharing based privacy computation requires one-time random numbers for processing. Before constructing the TPU-based computation, we design a protocol called Random Tuple Generation Protocol (RTG). The goal of RTG is to let TPUs cooperatively generate random tuple \( \mathfrak {r}_{i}^{(1)},\cdots, \mathfrak {r}_{i}^{(\ell)} \in \mathbb {Z}_{2}\) and \(r_{i} \in \mathbb {D}_{N}\) for each TPU i\((i = 1,\cdots, {\mathcal {P}})\), such that \(r = -\mathfrak {r}^{(\ell)}2^{\ell -1} + \sum _{j =1}^{\ell -1} \mathfrak {r}^{(j)} 2^{j-1}\) and \(\mathfrak {r}^{(j)} = \mathfrak {r}_{1}^{(j)} \oplus \cdots \oplus \mathfrak {r}_{\mathcal {P}}^{(j)}\) and \(r = r_{1} +\cdots + r_{\mathcal {P}}\) holds, where ℓ is the bit-length of random number \(r \in \mathbb {D}_{N}\). The RTG generates as follows:
1) The TPU 1 randomly generates \(\mathfrak {r}_{1}^{(1)},\cdots, \mathfrak {r}_{1}^{(\ell)} \in \mathbb {Z}_{2}\), encrypts them as \([\!\![\mathfrak {r}^{(1)}_{1}]\!\!],\cdots,[\!\![\mathfrak {r}^{(\ell)}_{1}]\!\!]\), denotes them as \([\!\![\mathfrak {r}^{(1)}]\!\!],\cdots,[\!\![\mathfrak {r}^{(\ell)}]\!\!]\), and sends these ciphertexts to TPU 2.
2) The TPU i (\(i=2,\cdots, {\mathcal {P}}\)) generates \(\mathfrak {r}_{i}^{(1)},\cdots, \mathfrak {r}_{i}^{(\ell)} \in \mathbb {Z}_{2}\) and computes \([\!\![\mathfrak {r}^{(j)}]\!\!] \leftarrow [\!\![\mathfrak {r}^{(j)}]\!\!]^{(1- \mathfrak {r}_{i}^{(j)})} \cdot \left ([\!\![1]\!\!] \cdot [\!\![\mathfrak {r}^{(j)}]\!\!]^{N-1}\right)^{\mathfrak {r}_{i}^{(j)}} = [\!\![\mathfrak {r}^{(j)} \oplus \mathfrak {r}_{i}^{(j)}]\!\!]\).
If \(i \neq {\mathcal {P}}\), the TPU i sends \([\!\![\mathfrak {r}^{(1)}]\!\!],\cdots,[\!\![\mathfrak {r}^{(\ell)}]\!\!]\) to TPU i+1. If \(i = {\mathcal {P}}\), the TPU \(\mathcal {P}\) computes \( [\!\![r]\!\!] \leftarrow [\!\![\mathfrak {r}^{(\ell)}]\!\!]^{N-2^{\ell -1}} \cdot [\!\![\mathfrak {r}^{(\ell -1)}]\!\!]^{2^{\ell -2}} \cdot \cdots \cdot [\!\![\mathfrak {r}^{(1)}]\!\!].\)
3) For TPU i\((i = {\mathcal {P}},\cdots, 2)\), randomly generates \(r_{i} \in \mathbb {D}_{N}\) and computes \( [\!\![r]\!\!] \leftarrow [\!\![r]\!\!] \cdot [\!\![-r_{i}]\!\!],\) and sends [ [r] ] to TPU i−1. Once TPU 1 gets [ [r] ], uses SDD to get r, and denotes ⌈r⌋N as r1. After computation, each TPU i\((i = 1,\cdots, {\mathcal {P}})\) holds randomly bits \(\mathfrak {r}_{i}^{(1)},\cdots, \mathfrak {r}_{i}^{(\ell)}\in \mathbb {Z}_{2}\) and integer \(r_{i} \in \mathbb {D}_{N}\).
Share domain transformation
Binary share to integer share transformation (B2I)
Suppose TPU i hold a bit share \(\mathfrak {a}_{i} \in \mathbb {Z}_{2}\), where \(\mathfrak {a}_{1} \oplus \cdots \oplus \mathfrak {a}_{\mathcal {P}} = \mathfrak {s} \in \mathbb {Z}_{2}\), the goal of the protocol is to generate a random integer share \( {b}_{i} \in \mathbb {Z}_{N}\) for each TPU i, such that \( {b}_{1} + \cdots + {b}_{\mathcal {P}} = \mathfrak {s} \). To execute B2I, the TPU 1 randomly generates \( {b}_{1} \in \mathbb {Z}_{N}\), denotes x=b1 and \( \mathfrak {s} = \mathfrak {a}_{1} \), encrypts x as [ [x] ], \(\mathfrak {s}\) as \([\!\![ \mathfrak {s}]\!\!] \), and sends [ [x] ] and \([\!\![\mathfrak {s}]\!\!] \) to TPU 2. After that, the TPU i\((i=2,\cdots, {\mathcal {P}}-1)\) generates \( {b}_{i} \in \mathbb {Z}_{N}\) and computes
and sends \([\!\![ x]\!\!], [\!\![ \mathfrak {s}]\!\!] \) to TPU i+1. Once received the \([\!\![ x]\!\!], [\!\![ \mathfrak {s}]\!\!]\), TPU \({\mathcal {P}}\) computes
and uses the SDD to decrypt and gets \( {b_{\mathcal {P}}}\).
Integer share to binary share transformation (I2B)
Suppose TPU i hold an integer share \( {a}_{i} \in \mathbb {Z}_{N}\), where \( {a}_{1} + \cdots + {a}_{\mathcal {P}} = \mathfrak {s} \in \mathbb {Z}_{2}\), the goal of the I2B protocol is to generate a random bit share \(\mathfrak {b}_{i} \in \mathbb {Z}_{2}\) for each TPU i, such that \( \mathfrak {b}_{1} \oplus \cdots \oplus \mathfrak {b}_{\mathcal {P}} = \mathfrak {s}\). To execute I2B, the TPU 1 lets y=a1, encrypts y as [ [y] ], and sends the ciphertext to TPU 2 for computation. After that, the TPU i\((i=2,\cdots, {\mathcal {P}})\) uses the share to compute \([\!\![y]\!\!] \leftarrow [\!\![y]\!\!] \cdot [\!\![a_{i}]\!\!] \). If \(i \neq {\mathcal {P}}\), TPU i sends [ [y] ] to TPU i+1. After that, denote \([\!\![\mathfrak {s} ]\!\!]\leftarrow [\!\![ y ]\!\!]\), and each TPU i\((i={\mathcal {P}},\cdots, 2)\) generates \(\mathfrak {b}_{i} \in \mathbb {Z}_{2}\) and computes
and sends \([\!\![\mathfrak {s}]\!\!]\) to TPU i−1. Once received \([\!\![\mathfrak {s}]\!\!]\), TPU 1 uses the SDD to decrypt \([\!\![\mathfrak {s}]\!\!]\) and denotes the result \(\mathfrak {s}\) as \( \mathfrak {b}_{1}\).
TPU-based secure outsourced computing toolkits in the cloud
In this section, we introduce and construct the commonly used secure outsourced binary and integer computation sub-protocols for a single cloud.
Secure computation over binary shares
Secure bit multiplication protocol (SBM)
The SBM can achieve plaintext multiplication on bit shares and output bit shares, i.e., given two shares \( \mathfrak {x}_{i}, \mathfrak {y}_{i} \in \mathbb {Z}_{2}\)\((i = 1,\cdots,{\mathcal {P}})\) for TPU i as input, SBM securely outputs \( \mathfrak {f}_{i} \in \mathbb {Z}_{2}\) for TPU i, such that \(\bigoplus _{i=1}^{\mathcal {P}} \mathfrak {f}_{i} = (\bigoplus _{i=1}^{\mathcal {P}} \mathfrak {x}_{i}) \land (\bigoplus _{i=1}^{\mathcal {P}} \mathfrak {y}_{i}).\)
Offline Stage: All the TPUs initialize their enclaves and load the public parameters to UnS. For enclave 1, generate \(\mathfrak {a}_{1}, \mathfrak {b}_{1} \in \mathbb {Z}_{2}\), compute \(\mathfrak {c} = \mathfrak {a}_{1} \cdot \mathfrak {b}_{1} \in \mathbb {Z}_{2}\). Encrypt \([\!\![\mathfrak {a}_{1}]\!\!],[\!\![\mathfrak {b}_{1}]\!\!] \) and \([\!\![\mathfrak {c}]\!\!]\), and denote them as \([\!\![\mathfrak {a}]\!\!],[\!\![\mathfrak {b}]\!\!], [\!\![\mathfrak {c}]\!\!]\), respectively. After that, TPU enclave i\((i = 1,\cdots, {\mathcal {P}}-1)\) sends \([\!\![\mathfrak {a}]\!\!], [\!\![\mathfrak {b}]\!\!], [\!\![\mathfrak {c}]\!\!]\) to enclave i+1, TPU i+1 generates \(\mathfrak {a}_{i+1}, \mathfrak {b}_{i+1}\) and computes
After the above computations, enclave i\((i = {\mathcal {P}},\cdots, 2)\) randomly generates \(\mathfrak {c}_{i} \in \mathbb {Z}_{N}\) and computes \([\!\![\mathfrak {c}]\!\!] \leftarrow [\!\![\mathfrak {c}]\!\!]^{(1- \mathfrak {c}_{i})} \cdot ([\!\![1]\!\!] \cdot [\!\![\mathfrak {c}]\!\!]^{N-1})^{\mathfrak {c}_{i}} = [\!\![\mathfrak {c} \oplus \mathfrak {c}_{i}]\!\!]\). When the TPU 2 sends \([\!\![\mathfrak {c}]\!\!]\) to TPU 1, the TPU 1 uses SDD to get \(\mathfrak {c}\) and denotes as \(\mathfrak {c}_{1} \leftarrow \mathfrak {c}\). After the above computations, each enclave holds \(\mathfrak {a}_{i}, \mathfrak {b}_{i}, \mathfrak {c}_{i}\), which satisfies \(\mathfrak {a}_{1}\oplus \cdots \oplus \mathfrak {a}_{\mathcal {P}} = \mathfrak {a}\), \(\mathfrak {b}_{1} \oplus \cdots \oplus \mathfrak {b}_{\mathcal {P}} = \mathfrak {b}\), \(\mathfrak {c}_{1} \oplus \cdots \oplus \mathfrak {c}_{\mathcal {P}} = \mathfrak {c}\) and \(\mathfrak {c} = \mathfrak {a} \land \mathfrak {b}\). Finally, each TPU i seals \(\mathfrak {a}_{i}, \mathfrak {b}_{i},\mathfrak {c}_{i}\) to UnS for storage individually.
Online Stage: For each TPU i\((i = 1,\cdots, {\mathcal {P}})\), load the \(\mathfrak {a}_{i}, \mathfrak {b}_{i}, \mathfrak {c}_{i}\) into the enclave i. Then, compute \(X_{i} = \mathfrak {x}_{i} \oplus \mathfrak {a}_{i} \) and \(Y_{i} = \mathfrak {y}_{i} \oplus \mathfrak {b}_{i}\). Securely send Xi and Yi to other enclave j\((j = 1,\cdots,{\mathcal {P}}; j \neq i)\). After receiving other Xj and Yj, each TPUs computes \(X = \bigoplus _{i=1}^{{\mathcal {P}}}X_{j}\) and \(Y = \bigoplus _{i=1}^{{\mathcal {P}}} Y_{j}\). For TPU i\((i = 1,\cdots, {\mathcal {P}}-1)\), compute \(\mathfrak {f}_{i}\leftarrow \mathfrak {c}_{i} \oplus (\mathfrak {b}_{i} \land X) \oplus (\mathfrak {a}_{i} \land Y)\). Then, TPU \({\mathcal {P}}\) computes \(\mathfrak {f}_{\mathcal {P}} \leftarrow \mathfrak {c}_{\mathcal {P}} \oplus (\mathfrak {b}_{\mathcal {P}} \land X) \oplus (\mathfrak {a}_{\mathcal {P}} \land Y) \oplus (X \land Y)\). Here, we denote the protocol as \(\langle \mathfrak {f} \rangle \leftarrow \texttt {SBM}(\langle \mathfrak {x} \rangle,\langle \mathfrak {y}\rangle)\).
Secure bit-wise addition protocol (BAdd)
The BAdd describes as follows: the TPU i holds bit shares \(\mathfrak {a}_{i}^{(\ell)},\cdots, \mathfrak {a}_{i}^{(1)}\) of ℓ bit-length integer a and \(\mathfrak {r}_{i}^{(\ell)},\cdots, \mathfrak {r}_{i}^{(1)}\) of ℓ bit-length integer r. The goal is to compute \(\mathfrak {y}_{i}^{(\ell)},\cdots, \mathfrak {y}_{i}^{(1)}\), such that y=a+r, where \( {y} = - \mathfrak {y}^{(\ell)} 2^{\ell -1} + \sum _{j=1}^{\ell -1} \mathfrak {y}^{(j)} 2^{j-1} \), \(\mathfrak {a}^{(j)} = \mathfrak {a}^{(j)}_{1} \oplus \mathfrak {a}^{(j)}_{2} \oplus \cdots \oplus \mathfrak {a}^{(j)}_{\mathcal {P}}\), \(\mathfrak {y}^{(j)} = \mathfrak {y}^{(j)}_{1} \oplus \mathfrak {y}^{(j)}_{2} \oplus \cdots \oplus \mathfrak {y}^{(j)}_{\mathcal {P}}\) and \(\mathfrak {r}^{(j)} = \mathfrak {r}^{(j)}_{1} \oplus \mathfrak {r}^{(j)}_{2} \oplus \cdots \oplus \mathfrak {r}^{(j)}_{\mathcal {P}}\). The idea is easy and simple: use the binary addition circuit to achieve the addition, i.e, compute the integer addition as \(\mathfrak {y}^{(j)} = \mathfrak {a}^{(j)} \oplus \mathfrak {r}^{(j)} \oplus \mathfrak {c}^{(j)}\) and \(\mathfrak {c}^{(j+1)} = (\mathfrak {a}^{(j)} \land \mathfrak {r}^{(j)}) \oplus ((\mathfrak {a}^{(j)} \oplus \mathfrak {r}^{(j)}) \land \mathfrak {c}^{(j)})\) for j=1,⋯,ℓ. The procedure of BAdd works as follows:
1) For each TPU i\((i = 1,\cdots, {\mathcal {P}})\) and each bit position j=1,⋯,ℓ, all the TPUs jointly compute \(\mathfrak {d}_{i}^{(j)} \leftarrow \mathfrak {a}_{i}^{(j)} \oplus \mathfrak {r}_{i}^{(j)}\) and \( \langle \mathfrak {e}^{(j)} \rangle \leftarrow \texttt {SBM}(\langle \mathfrak {a}^{(j)} \rangle, \langle \mathfrak {r}^{(j)} \rangle)\). After using the computation of SBM, it indeed computes \(\mathfrak {e}^{(j)} = \mathfrak {a}^{(j)} \land \mathfrak {r}^{(j)}.\)
2) Each TPU i sets \(\mathfrak {c}_{i}^{(1)} \leftarrow 0\) and \(\mathfrak {y}_{i}^{(1)} \leftarrow \mathfrak {d}_{i}^{(1)}\). Then, for j=2,⋯,ℓ, all TPUs jointly computes
Moreover, for each TPU i locally computes
and outputs \(\mathfrak {y}_{i}^{(j)} \) for all j.
Secure bit extraction protocol (BExt)
Suppose TPU i\((i=1,\cdots,{\mathcal {P}})\) contains an integer share ui, where \(u = \sum _{i=1}^{{\mathcal {P}}} u_{i}\). The goal of BExt is to output the bit extraction shares \(\mathfrak {u}^{(\ell)}_{i},\cdots, \mathfrak {u}^{(1)}_{i}\) for each TPU i (\(i = 1,\cdots, {\mathcal {P}}\)), where \( {u} = - \mathfrak {u}^{(\ell)} 2^{\ell -1} + \sum _{j=1}^{\ell -1} \mathfrak {u}^{(j)} 2^{j-1} \) and \(\mathfrak {u}^{(j)} = \bigoplus _{i=1}^{{\mathcal {P}}} \mathfrak {u}^{(j)}_{i}\). The BExt also contains offline/online phase which describes as follows:
Offline Phase: Execute RTG to get \(\mathfrak {r}_{i}^{(\ell)},\cdots, \mathfrak {r}_{i}^{(1)}\) and ri for party i. Then, all the TPUs need to jointly compute \(\mathfrak {a}^{(\ell)},\cdots, \mathfrak {a}^{(1)} \in \mathbb {Z}_{2}\), such that \(\mathfrak {a}^{(\ell)} \oplus \cdots \oplus \mathfrak {a}^{(1)} = 0\). Firstly, TPU 1 randomly generates \(\mathfrak {a}_{1}^{(\ell)},\cdots, \mathfrak {a}_{1}^{(1)} \in \mathbb {Z}_{2}\) and let \(\mathfrak {t}^{(j)} = \mathfrak {a}_{1}^{(j)} \) for j=1,⋯ℓ. After that, the TPU i generates \(\mathfrak {a}_{i}^{(\ell)},\cdots, \mathfrak {a}_{i}^{(1)} \in \mathbb {Z}_{2}\), computes
and sends these ciphertexts to TPU i+1. Once the \([\!\![\mathfrak {t}^{(\ell -1)}]\!\!],\cdots, [\!\![\mathfrak {t}^{(0)}]\!\!] \) are received, the TPU \({\mathcal {P}}\) uses the SDD to decrypt, gets \(\mathfrak {t}^{(\ell)},\cdots, \mathfrak {t}^{(1)}\) and denotes them as \(\mathfrak {a}_{\mathcal {P}}^{(\ell)},\cdots, \mathfrak {a}_{\mathcal {P}}^{(1)}\). After that, each TPU i seals \(\mathfrak {r}_{i}^{(\ell)},\cdots, \mathfrak {r}_{i}^{(1)},\)ri,\(\mathfrak {a}_{i}^{(\ell)},\cdots, \mathfrak {a}_{i}^{(1)}\) in UnS, respectively.
Online Phase: The TPU i computes vi=ui−ri, encrypts vi and sends [ [vi] ] to TPU \({\mathcal {P}}\). After received all the encryptions, the TPU \({\mathcal {P}}\) computes \([\!\![v]\!\!] \leftarrow \prod _{i=1}^{{\mathcal {P}}} [\!\![v_{i}]\!\!]\) and executes SDD to get the v, and computes ⌈v⌋N. Then, TPU \({\mathcal {P}}\) generates its twos complement binary representation \(\mathfrak {v}^{(\ell -1)},\cdots, \mathfrak {v}^{(0)},\) and computes \(\mathfrak {v}^{(j)}_{\mathcal {P}} \leftarrow \mathfrak {v}^{(j)} \oplus \mathfrak {a}_{\mathcal {P}}^{(j)}\), where j=1,⋯,ℓ. Other TPU i\((i = 1,\cdots,{\mathcal {P}}-1)\) keeps other \(\mathfrak {v}^{(\ell)}_{i} \leftarrow \mathfrak {a}^{(\ell)}_{i},\cdots, \mathfrak {v}^{(1)}_{i} \leftarrow \mathfrak {a}^{(1)}_{i}\) unchanged.
After that, all the TPUs jointly compute
where \(\vec {\mathfrak {u}}_{i} = \left (\mathfrak {u}_{i}^{(\ell)},\cdots, \mathfrak {u}_{i}^{(1)}\right)\), \(\vec {\mathfrak {v}}_{i} = \left (\mathfrak {v}_{i}^{(\ell)},\cdots, \mathfrak {v}_{i}^{(1)}\right)\), \(\vec {\mathfrak {r}}_{i} = \left (\mathfrak {r}_{i}^{(\ell)},\cdots, \mathfrak {r}_{i}^{(1)}\right)\). Finally, the BExt algorithm outputs \(\vec {\mathfrak {u}}_{i} = (\mathfrak {u}_{i}^{(\ell)},\cdots, \mathfrak {u}_{i}^{(1)})\) for TPU \(i = 1,\cdots, {\mathcal {P}}\).
Secure integer computation
Secure multiplication protocol (SM)
The SM achieves integer multiplication over integer shares, i.e., given shares xi,yi\((i = 1,\cdots, {\mathcal {P}})\) for TPU i as input, SM securely outputs fi for TPU i, such that \(\sum _{i=1}^{\mathcal {P}} f_{i} = x \cdot y,\) where data shares xi,yi satisfy \(x = \sum _{i=1}^{\mathcal {P}} x_{i}\) and \(y = \sum _{i=1}^{\mathcal {P}} y_{i}\).
Offline Stage: All the TPUs initialize their enclaves and load the public parameters to the UnS. Then, for the enclave 1, it generates \(a_{1}, b_{1} \in \mathbb {D}_{N}\), computes z=a1·b1, encrypts [ [a1] ],[ [b1] ],[ [z] ], and lets them be [ [a] ],[ [b] ],[ [c] ], respectively. After that, enclave i (\(i = 1,\cdots,{\mathcal {P}}-1\)) sends [ [a] ],[ [b] ],[ [c] ] to enclave i+1, TPU i+1 generates ai+1,bi+1 and computes
After the computation, for \(i = {\mathcal {P}},\cdots, 2\), TPU enclave i generates \(c_{i} \in \mathbb {D}_{N}\) and computes [ [c] ]=[ [c] ]·[ [ci] ]N−1. After the computation, the TPU 2 sends [ [c] ] to TPU 1. Then, TPU 1 uses SDD to get c and denotes the final result ⌊c⌉N as c1. After the above computation, each enclave hold ai,bi,ci, such that \( \lceil a_{1}+\cdots + a_{\mathcal {P}} \rfloor _{N} = \lceil a \rfloor _{N}\), \(\lfloor b_{1} +\cdots + b_{\mathcal {P}} \rceil _{N} = \lceil b \rfloor _{N}\), \(\lceil c_{1} + \cdots + c_{\mathcal {P}} \rfloor _{N} = \lceil c \rfloor _{N}\) and c=a·b mod N. After the computation, each TPU enclave i seals ai,bi,ci to UnS for storage individually.
Online Stage: TPU i loads the ai,bi,ci into the enclave i. Then, compute Xi=xi−ai and Yi=yi−bi. Securely send Xi and Yi to other enclave j\((j = 1,\cdots,{\mathcal {P}}; j \neq i)\). After receiving other Xj and Yj, the each TPU i computes \(X = \sum _{i=1}^{{\mathcal {P}}}X_{j}\) and \(Y = \sum _{i=1}^{{\mathcal {P}}} Y_{j}\). After that, for each TPU i\((i = 1,\cdots, {\mathcal {P}}-1)\), compute \(f_{i}\leftarrow \lceil c_{i} + b_{i} X + a_{i} Y \rfloor _{N} \). For TPU \({\mathcal {P}}\), compute \(f_{\mathcal {P}} \leftarrow \lceil c_{\mathcal {P}} + b_{\mathcal {P}} X + a_{\mathcal {P}} Y + X \cdot Y \rfloor _{N}\). Here, we denote the protocol as \( \langle f \rangle \leftarrow \texttt {SM}(\langle x \rangle,\langle y\rangle)\).
Secure Monic monomials computation (SMM)
The SMM protocol can achieve monic monomials computation over integer shares, i.e., given a share xi\((i = 1,\cdots, {\mathcal {P}})\) and a public integer number k for TPU i as input, SMM securely outputs fi for TPU i, such that \(\sum _{i=1}^{\mathcal {P}} f_{i} = x^{k},\) where data shares xi satisfy \(x = \sum _{i=1}^{\mathcal {P}} x_{i}\). The construction of the SMM is list as follows: Denote k as binary form \(\mathfrak {k}_{\ell },\cdots, \mathfrak {k}_{1}\). Initialize the share \(f_{i} \leftarrow x_{i}\) for each TPU i. For j=ℓ−1,⋯,1, compute \( \langle f^{*} \rangle \leftarrow \texttt {SM}(\langle f \rangle,\langle f \rangle)\). If \(\mathfrak {k}_{j} = 1\), compute \( \langle f \rangle \leftarrow \texttt {SM}(\langle f^{*} \rangle,\langle x \rangle)\). Otherwise, let \( \langle f \rangle \leftarrow \langle f^{*} \rangle \). Here, the algorithm outputs 〈f〉 and denotes the protocol as \( \langle f \rangle \leftarrow \texttt {SMM}(\langle x \rangle, k)\).
Secure binary exponential protocol (SEP2)
The SEP2 can achieve exponential over binary shares with a public base, i.e., given a binary share \(\mathfrak {x}_{i} \in \mathbb {Z}_{2}\)\((i = 1,\cdots, {\mathcal {P}})\) and a public integer β for TPU i as inputFootnote 14, SEP2 securely outputs an integer share \(f_{i} \in \mathbb {Z}_{N}\) for TPU i, such that \(\sum _{i=1}^{\mathcal {P}} f_{i} = \beta ^{\mathfrak {x}},\) where \(\mathfrak {x} = \bigoplus _{i=1}^{{\mathcal {P}}} \mathfrak {x}_{i}\).
Offline Stage: All the TPUs initialize their enclaves and load the public parameters to the UnS. Then, for the enclave 1, it generates \({\mathfrak {a}}_{1}\in \mathbb {Z}_{2}\), encrypts \(\mathfrak {a}_{1}\) as \([\!\![\mathfrak {a}_{1}]\!\!]\), and lets it be \([\!\![\mathfrak {a}]\!\!] \). After that, enclave i (\(i = 1,\cdots,{\mathcal {P}}-1\)) sends \([\!\![\mathfrak {a}]\!\!] \) to enclave i+1, TPU i+1 generates \(\mathfrak {a}_{i+1} \in \mathbb {Z}_{2}\), computes
Once \([\!\![\mathfrak {a}]\!\!]\) is received, TPU \({\mathcal {P}}\) computes
After the computation, for \(i = {\mathcal {P}},\cdots, 2\), TPU i generates \(b_{i}, b^{*}_{i} \in \mathbb {D}_{N}\) and computes [ [b] ]=[ [b] ]·[ [bi] ]N−1 and \([\!\![b^{*}]\!\!] = [\!\![b^{*}]\!\!] \cdot [\!\![b^{*}_{i}]\!\!]^{N-1}.\) After the computation, the TPU 2 sends [ [b] ] and [ [b∗] ] to TPU 1, and TPU 1 uses SDD to get b, b∗ and denote them as b1 and \(b^{*}_{1}\), respectively. After the above computation, each TPU i holds \(\mathfrak {a}_{i}, b_{i}\), which satisfies \( \mathfrak {a}_{1}\oplus \cdots \oplus \mathfrak {a}_{\mathcal {P}} = \mathfrak {a}\), \( b_{1}+ \cdots + b_{\mathcal {P}} = \beta ^{\mathfrak {a}}\), \( b^{*}_{1}+ \cdots + b^{*}_{\mathcal {P}} = \beta ^{1-\mathfrak {a}}\). After the computation, each TPU i seals \( \mathfrak {a}_{i}, b_{i}\) to UnS for storage individually.
Online Stage: TPU i loads the data share \(\mathfrak {x}_{i}\) and random shares \(\mathfrak {a}_{i}, b_{i}\) into the its enclave. Then, TPU i locally computes \(X_{i} = {\mathfrak {x}_{i} \oplus \mathfrak {a}_{i}} \). Securely send Xi to other enclave j\((j = 1,\cdots,{\mathcal {P}}; j \neq i)\). After receiving other Xj, each TPU i locally computes \(X = \bigoplus _{i=1}^{{\mathcal {P}}}X_{i}\) and \(f_{i}\leftarrow \lceil (b^{*}_{i})^{X} \cdot (b_{i})^{1-X} \rfloor _{N}\). We can easily verify that \(\sum _{i=1}^{\mathcal {P}} f_{i} = \beta ^{(1-\mathfrak {a})({\mathfrak {x} \oplus \mathfrak {a}})+ \mathfrak {a}{(1-\mathfrak {x} \oplus \mathfrak {a}})}= \beta ^{\mathfrak {x}}\). Here, we denote the protocol as \( \langle f \rangle \leftarrow \texttt {SEP}_{2}(\langle {\mathfrak {x}} \rangle, \beta)\).
Secure integer exponential protocol (SEP)
The SEP can achieve exponential over integer shares with a public base, i.e., given an integer share \(x_{i} \in \mathbb {D}_{N}\)\((i = 1,\cdots, {\mathcal {P}})\) and a public integer β for TPU i as input, SEP securely outputs shares \(f_{i} \in \mathbb {D}_{N}\) for TPU i, such that \(\sum _{i=1}^{\mathcal {P}} f_{i} = \beta ^{x},\) where data shares xi satisfy \(x = \sum _{i=1}^{\mathcal {P}} x_{i}\) and x is relative small positive number with ℓ bit-length.
i) Compute \((\vec {\mathfrak {x}}_{1},\cdots,\vec {\mathfrak {x}}_{\mathcal {P}}) \leftarrow \texttt {BExt} (x_{1},\cdots,x_{\mathcal {P}}),\) where \(\vec {\mathfrak {x}}_{i} = (\mathfrak {x}_{i}^{(\ell)},\cdots, \mathfrak {x}_{i}^{(1)})\) for TPU \(i = 1,\cdots, {\mathcal {P}}\), and \( \mathfrak {x}^{(j)} = \bigoplus _{i=1}^{\mathcal {P}} \mathfrak {x}_{i}^{(j)}\), and \(x = \sum _{j=1}^{\ell } \mathfrak {x}^{(j)} 2^{j-1}.\)
ii) Execute \( \langle {\mathfrak {f}} \rangle \leftarrow \texttt {SEP}_{2} (\langle {\mathfrak {x}}^{(1)} \rangle, \beta).\) For j=2,⋯,ℓ, compute \( \langle { {f}}_{j} \rangle \leftarrow \texttt {SEP}_{2} (\langle {\mathfrak {x}}^{(j)} \rangle, \beta)\), \( \langle { {f}}^{*}_{j} \rangle \leftarrow \texttt {SMM} (\langle { {f}}_{j} \rangle, 2^{j-1})\), and \( \langle { {f}} \rangle \leftarrow \texttt {SM} (\langle { {f}} \rangle, \langle { {f}}^{*}_{j} \rangle)\). The SEP outputs 〈f〉, and we denote the protocol as \( \langle f \rangle \leftarrow \texttt {SEP}(\langle x \rangle,\beta)\).
Secure comparison protocol (SC)
The SC can securely compute the relationship between integer u and v, where each TPU i holds shares ui and vi, where \(u = u_{1} + \cdots + u_{{\mathcal {P}}}\), \(v = v_{1} + \cdots + v_{{\mathcal {P}}}\). The construction of SC is listed as follows:
i) Each TPU i (\(i =1,\cdots, {\mathcal {P}}\)) locally computes wi=ui−vi. After that, all TPUs jointly compute
ii) As we use twos complement binary representation, the most significant digit of u−v will reflect the relationship between the u and v. After the above computation, TPU i outputs \(\mathfrak {w}_{i}^{(\ell -1)} \in \vec {\mathfrak {w}}_{i}\). The most significant digit \(\mathfrak {w}^{(\ell -1)}\) of \(w = \sum _{i=1}^{\mathcal {P}} w_{i}\) decides the relationship of u and v, specifically, if \(\bigoplus _{i=1}^{\mathcal {P}} \mathfrak {w}_{i}^{(\ell -1)} = 0\), it denotes u≥v. Otherwise, it denotes u<v.
Secure equivalent protocol (SEQ)
The goal of secure equivalent protocol SEQ is to test whether the two values u,v are equal or not by giving the shares of the two values 〈u〉,〈v〉. Mathematically, given two shares 〈u〉 and 〈v〉, SEQ (Liu et al. 2016a) outputs the shares \(\mathfrak {f}_{i}\) for each TPU i\((i=1,\cdots, {\mathcal {P}})\) to determine whether the plaintext of the two data are equivalent (i.e. test u=?v. If \(\bigoplus ^{\mathcal {P}}_{i=1} \mathfrak {f}_{i} = 1 \), then u=v; otherwise, u≠v). The SEQ is described as follows:
i) All the TPUs jointly calculate
ii) For each TPU i, it computes \(\mathfrak {f}_{i} = \mathfrak {t}^{*}_{1,i} \oplus \mathfrak {t}^{*}_{2,i}\) locally, and outputs \(\mathfrak {f}_{i} \in \mathbb {Z}_{2}\).
Secure minimum of two number protocol (Min2)
The TPU i\((i=1,\cdots, {\mathcal {P}})\) stores shares 〈x〉 and 〈y〉 of two numbers x and y, The Min2 protocol outputs share 〈B〉 of minimum number B, s.t., B=min(x,y). The Min2 is described as follows:
i) All the TPUs can jointly compute
ii) The TPU i computes locally and outputs Bi=yi−Yi+Xi.
Secure minimum of H numbers protocol (MinH)
The goal of MinH is to get the minimum number among H numbers. Given the shares x1,i,⋯,xH,i for TPU i, the goal is to compute the share \( x^{*}_{i}\) for TPU i such that x∗ stores the minimum integer value among x1,⋯,xH, where \(x^{*} = \sum _{i=1}^{{\mathcal {P}}} x^{*}_{i}\), \(x_{j} = \sum _{i=1}^{\mathcal {P}} x_{i,j}\) for j=1,⋯,H. The MinH executes as follows: Each TPU i puts x1,i,⋯,xH,i into a set Si. If \( {\mathcal {L}} ({S_{i}}) = 1\), the share remaining in \({\mathcal {L}}({S_{i}}) \) is the final output. Otherwise, the protocol is processed according to the following conditions.
∙ If \( {\mathcal {L}}({S_{i}}) \mod 2=0\) and \({\mathcal {L}}({S_{i}}) > 1\), 1) set \(S^{\prime }_{i} \leftarrow \emptyset \); 2) for \(j = 1,\cdots, {\mathcal {L}}({S_{i}}) /2 \), compute
and add xj,i to the set \(S^{\prime }_{i}\); 3) clear set Si and let \({S_{i}} \leftarrow S'_{i} \).
∙ If \( {\mathcal {L}}({S_{i}}) \mod 2 \neq 0\) and \( {\mathcal {L}}({S_{i}}) > 1\), take out the last tuple \( x_{{\mathcal {L}}({S_{i}})-1,i} \) from set Si s.t., \( {\mathcal {L}}({S_{i}}) \mod 2=0\). Run the above procedure (\( {\mathcal {L}}({S_{i}}) \mod 2=0\) and \( {\mathcal {L}}({S_{i}}) > 1\)) to generate set \(S^{\prime }_{i}\). Put \( x_{{\mathcal {L}}({S_{i}}) -1,i} \) into a set Si′ and denote \(S_{i}' \leftarrow S_{i}\).
After computation, each set Si in TPU i only contains one element and we denote it as \(x^{*}_{i}\). Thus, we denote the protocol as \( \langle x^{*} \rangle \leftarrow \texttt {Max}_{H}(\langle x_{1} \rangle, \cdots, \langle x_{H} \rangle).\)
Security extension of integer computation
The above secure computation only considers data privacy. Two types of information can be leaked to the adversary: 1) the access pattern of function’s input, and 2) the access pattern of RU’s result retrieve. Here, we give two security extensions to achieve access pattern hiding and private information retrieval, respectively.
Achieve input access pattern hiding (APH)
As data are directly sealed in the UnS, the adversary may analysis the access pattern of UnS without knowing the function’s input. Suppose the system contains H data \(x^{*}_{1},\cdots,x^{*}_{H} \in \mathbb {D}_{N}\). The data shares xj,i are hold by each TPU i\((j = 1,\cdots,H; i = 1,\cdots, \mathcal {P})\), such that \(x_{j,1}+\cdots +x_{j,{\mathcal {P}}} = x^{*}_{j}\). To achieve access pattern hiding, the homomorphic property of PCDD can be used. Specifically, the RU uploads [ [a1] ],⋯,[ [aH] ] to each TPU i, s.t., for a specific 1≤γ≤H, it has aγ=1, and other j≠γ and 1≤j≤H, it holds aj=0. Then, the goal of the algorithm is to securely select the shares of xγ,j from the input shares, and constructs as follows:
1) Obviously select encrypted shares. Each TPU initializes an enclave. Then, for each TPU i\((i=1,\cdots, {\mathcal {P}})\), compute
2) Securely update share [ [bi] ] for TPU i. Without any share update, the adversary can still know the access pattern once the ciphertexts are decrypted. Thus, all the shares should be dynamically updated before the decryption.
The TPU i picks random numbers \(\delta _{i,1},\cdots,\delta _{i, {\mathcal {P}}} \in \mathbb {Z}_{N}\) such that \(\delta _{i,1}+\cdots +\delta _{i, {\mathcal {P}}} = 0 \mod N\), and then encrypts δi,j and sends [ [δi,j] ] to TPU enclave j. Once all the update shares are received, TPU i computes
Finally, each TPU i uses the SDD to get \(b^{*}_{i}\) and denotes \(\lceil b^{*}_{i} \rfloor _{N}\) as the final share output.
Achieve private information retrieve (PIR)
If the computation results are needed, the RU will let the TPU send the data shares back via a secure channel. However, if one of the TPU has been compromised, the adversary will know the retrieve access pattern even if the data are encrypted. Suppose the system contains H data \(x^{*}_{1},\cdots,x^{*}_{H} \in \mathbb {D}_{N}\). The data share xj,i are hold by each TPU i\((j = 1,\cdots,H; i = 1,\cdots, \mathcal {P})\), such that \(x_{j,1}+\cdots +x_{j,{\mathcal {P}}} = x^{*}_{j}\). Thus, to achieve the private information retrieve, the RU uploads [ [a1] ],⋯,[ [aH] ] to each TPU, s.t., for a specific 1≤γ≤H, it has aγ=1, and other j≠γ,1≤j≤H, it holds aj=0. The goal of PIR is to let RU privately retrieve xγ. Then, the algorithm computes among all TPUs as follows:
1) For each TPU i, compute
2) TPU 1 denotes \([\!\![b^{*}]\!\!] \leftarrow [\!\![b_{1}]\!\!]\), and sends [ [b∗] ] to TPU 2. Then, each TPU \(i =2,\cdots, {\mathcal {P}}\), computes \([\!\![b^{*}]\!\!] \leftarrow [\!\![b^{*}]\!\!] \cdot [\!\![b_{i}]\!\!] \mod N^{2}\). If \(i = {\mathcal {P}}\), then send [ [b∗] ] to RU. Otherwise, [ [b∗] ] is sent from TPU i to i+1. Finally, RU uses the Dec to get the b∗, and denotes \(x_{\gamma } \leftarrow \lceil b^{*} \rfloor _{N}\) as final output.
Secure floating point number computation
Data format of floating-point number
To achieve the real number storage and computation, we can refer to the IEEE 754 standard to use Floating-Point Number (FPN) for real number storage. To support the LightCom, we change the traditional FPN and describe the FPN by four integers: 1) a radix (or base) β≥2; 2) a precision η≥2 (roughly speaking, η is the number of “significant digits” of the representation); 3) two extremal exponents emin and emax such that emin<0<emax. A finite FPN \(\hat {a}\) in such a format is a number for which there exists at least one representation two-tuple (m,e) with public parameters β,η,emin,emax, such that,
-
m is an integer which satisfied −βη+1≤m≤βη−1. It is called the integral significand of the representation of x;
-
e is an integer such that emin≤e≤emax, called the exponent of the representation of a.
As only the significand and exponent contains sensitive information, we assume all the FPNs have the same public base β=10, and use the fix bit-length to store the integer m. Thus, to achieve the secure storage, the RU only needs to random share the \(\hat {a}\) into \(\hat {a}_{1}=(m_{1},e_{1}),\cdots, \hat {a}_{\mathcal {P}}= (m_{\mathcal {P}},e_{\mathcal {P}})\), and sends \(\hat {a}_{i}\) to TPU i for storage, respectively.
For the secure FPN computation, if all the FPNs are transformed with the same exponential, we can directly use secure integer computation methods introduced in “TPU-based secure outsourced computing toolkits in the cloud” section. Thus, the critical problem to achieve secure FPN computation is how to allow all the FPNs securely transformed with the same exponential. Here, we first construct an algorithm called Secure Uniform Computation (UNI) and then achieve the commonly-used FPN computations.
Secure uniform computation (UNI)
Assume each TPU \(i (i=1,\cdots, {\mathcal {P}})\) stores into \(\hat {a}_{j,i}=(m_{j,i},e_{j,i})\), the goal of UNI is to output \(\hat {a}^{*}_{j,i}=(m^{*}_{j,i},e^{*})\) for j=1,⋯,H, and the construction of UNI can be described as follows:
i) All the TPUs jointly compute
ii) Each TPUs locally computes \(\langle c_{j} \rangle = {\langle e_{j} \rangle - \langle e^{*}_{i}}\rangle \). As ej−e∗ is a relative small number, TPUs jointly executes \( \langle 10^{ e_{j} - e^{*} } \rangle \leftarrow \texttt {SEP}(\langle c_{j} \rangle, 10)\) and \(\langle m^{*}_{j} \rangle \leftarrow \texttt {SM} (\langle 10^{ e_{j} - e^{*}} \rangle,\langle m_{j} \rangle)\).
After computation, all the 〈a1〉,⋯,〈aH〉 will transform to \(\langle a^{*}_{1} \rangle,\cdots, \langle a^{*}_{H} \rangle \) which shares the same e∗, where \(\langle \hat {a}^{*}_{j} \rangle = (\langle m^{*}_{j} \rangle, \langle e^{*} \rangle)\) for j=1,⋯,H.
Computation transformation
The secure floating-point number computation can be transformed into the secure integer computation protocols with the usage of UNI. Formally, given FPN shares \(\langle \hat {a}_{j}\rangle =(\langle m_{j} \rangle, \langle e_{j} \rangle) \), (for j=1,⋯,H), we can first compute
where \(\langle \hat {a}^{*}_{j}\rangle = (\langle {m}^{*}_{j}\rangle,\langle \hat {e}^{*}\rangle)\). Then,
where \(\mathcal {SIF}\) denote secure integer computation protocol designed in “TPU-based secure outsourced computing toolkits in the cloud” section, and \(\langle y^{*}_{1} \rangle,\cdots, \langle y^{*}_{\zeta } \rangle \) can be either integer shares or binary shares according to the function type. If the \({\mathcal {SIF}}\) is the SC and SEQ, then the \({\mathcal {SIF}}\) output the binary share \(\langle \mathfrak {y}^{*} \rangle \) as the final output, and we denote these two algorithms as secure FPN comparison (FC) and secure FPN equivalent test protocol (FEQ). If the \({\mathcal {SIF}}\) is the SM, SMM, Min2 and MinH, then the \({\mathcal {SIF}}\) outputs the integer share 〈y∗〉, and denotes \(\langle \hat {y}^{*} \rangle = (\langle {y}^{*} \rangle, \langle e^{*}\rangle)\) as the secure FPN’s output, and we denote above four algorithms as secure FPN multiplication (FM), secure FPN monic monomials computation (FMM), secure minimum of two FPNs protocol (FMin2), and secure minimum of H FPNs protocol (FMinH), respectively. Specifically, for the multiple FPN addition (FAdd), given FPN shares \(\langle \hat {a}_{j}\rangle =(\langle m_{j} \rangle, \langle e_{j} \rangle) \), (for j=1,⋯,H), we can first compute \(\langle \hat {a}^{*}_{1}\rangle,\cdots, \langle \hat {a}^{*}_{H}\rangle \) with the UNI, where \(\langle \hat {a}^{*}_{j}\rangle = (\langle {m}^{*}_{j}\rangle,\langle {e}^{*}\rangle)\). Then, compute \(\langle {y}^{*}\rangle \leftarrow \sum _{j=1}^{H} \langle {m}^{*}_{j}\rangle \) and denote the final FPN addition result as \(\langle \hat {y}\rangle = (\langle {y}^{*}\rangle, \langle {e}^{*}\rangle)\).
Secure extension for FPN computation
Similar to the secure integer computation, we have the three following extension for LightCom.
Access Pattern Hiding: As all the secure FPN computation can be transformed in to secure integer computation with the help of the UNI, we can also use the same method in “Achieve input access pattern hiding (APH)” section to achieve input access pattern hiding for the secure FPN computation.
Achieve Private FPN Retrieve: In out LightCom, one floating-point number is stored as two integer numbers. Thus, we can use the method in “Achieve private information retrieve (PIR)” section to privately retrieve integer for twice to achieve the private FPN retrieve.
Functional extension for LightCom
Non-numerical data storage and processing
For the non-numerical data storage, the traditional character encodings with Unicode (Consortium and et al. 1997) and its standard Unicode Transformation Format (UTF) scheme is used which maps a character into an integer. Specifically, for secure storage, use UTF-8 to map the character into 32-bit number x, randomly splits x into \(X_{1},\cdots,X_{\mathcal {P}}\), such that \(x_{1} +\cdots +x_{\mathcal {P}} = x \), and sends ai to TPU i for processing. In this case, all the non-numerical data processing can be transformed into secure integer computation which can be found in “TPU-based secure outsourced computing toolkits in the cloud” section. For the secure storage, each TPU i securely seals the share ai into the UnS with the algorithm Seal in “Secure TPU-based data seal & UnSeal” section. Once the data shares are needed for processing, TPUs need to use UnSeal algorithm to recover the message from UnS.
Extension of multiple user computation
All the secure computations in the previous section are designed for the single user setting, i.e., all the data are encrypted under a same RU’s public key. If all RUs want to jointly achieve a secure computation, each RU j(j=1,⋯,ψ) executes KeyGen to generate public key pkj and private key is skj locally. Then, RU j uses KeyS to split key skj into \(\mathcal {P}\) shares 〈skj〉, and sends these shares to TPUs in the cloud. Assume RU j’s ciphertext \([\!\![x_{j}]\!\!]_{pk_{j}}\phantom {\dot {i}\!}\) is securely stored in UnS, TPUs can get data shares 〈xj〉 with UnSeal and achieve the corresponding secure computations GenCpt in Section 3 with these shares.
Security analysis
In this section, we first analyze the security of the basic crypto primitives and the sub-protocols, before demonstrating the security of our LightCom framework.
Analysis of basic crypto primitives
The security of secret sharing scheme
Here, we give the following theorem to show the security of the additive secret sharing scheme.
Theorem 1
An additive secret sharing scheme achieves an information-theoretic secure when the \(\mathcal {P}\) participants can reconstruct the secret \(x \in \mathbb {G}\), while any smaller set cannot discover anything information about the secret.
Proof
The shares \(X_{1},\cdots,X_{\mathcal {P}}\) are selected with random uniform distribution among \(\mathcal {P}\) participants such that \(X_{1}+\cdots +X_{\mathcal {P}} = m \in \mathbb {G}\). Even the attacker \(\mathcal {A}\) holds \({\mathcal {P}}-1\) shares, (s)he can only compute \(x' = \sum _{i=1}^{{{\mathcal {P}}-1}} X'_{i}\), where \(X^{\prime }_{i}\) is selected from \(X_{1},\cdots, X_{\mathcal {P}}\). The element x is still protected due to the \(x = x' + X'_{{\mathcal {P}}}\). Since random value \(X^{\prime }_{{\mathcal {P}}}\) is unknown for \(\mathcal {A}\), it leaks no information about the value x. □
Theorem 2
A proactive additive secret sharing scheme achieves an information-theoretic secure if the scheme satisfies the following properties: I. Robustness: The newly updated shares correspond to the secret x (i.e., all the new shares can reconstruct the secret x). II. Secrecy: The adversary at any period knows no more than \(\mathcal {P}\) shares (possible a different share in each period) learns nothing about the secret.
Proof
The data shares \(X^{(t)}_{i}\) in time period t are stored in party i, s.t., \(\sum _{i=1}^{\mathcal {P}}X^{(t)}_{1}=x\). Each party i generates shares \(\delta ^{(t)}_{i,1},\cdots, \delta ^{(t)}_{i,{\mathcal {P}}}\) which satisfies \(\delta ^{(t)}_{i,1}+\cdots +\delta ^{(t)}_{i,{\mathcal {P}}} = 0 \mod N\). Thus, the new shares denote \(X^{(t+1)}_{i} = X^{(t)}_{i} + \delta ^{(t)}_{1,i} + \cdots + \delta ^{(t)}_{{\mathcal {P}},i}\), and satisfy \(\sum _{i=1}^{\mathcal {P}} X_{i}^{(t+1)} = \sum _{i=1}^{\mathcal {P}} X_{i}^{(t+1)} + \sum _{i=1}^{\mathcal {P}}\sum _{i=1}^{\mathcal {P}}\delta ^{(t)}_{i,j} = x\) which the robustness property hold.
To guarantee the secrecy property, the data shares in time period t can achieve the information theoretic secure according to the Theorem 1. Even adversary can get \({\mathcal {P}} -1\) shares in each time period t (t≤t∗), the adversary can compute \(x^{(t)} = x - X^{(t)}_{{\mathcal {P}}_{t}} = \sum _{i=1, i \neq {\mathcal {P}}_{t}}^{\mathcal {P}} X_{i}^{(t)}\), where \(X^{(t)}_{{\mathcal {P}}_{t}}\) is the non-compromised share in time period t. The adversary \(\mathcal {A}^{*}\phantom {\dot {i}\!}\) still cannot get any information from \(\phantom {\dot {i}\!}x^{(1)},\cdots,x^{(t_{*})}\) as \(\delta ^{(1)}_{{\mathcal {P}}_{1},{\mathcal {P}}_{1}},\cdots,\delta ^{(t_{*})}_{{\mathcal {P}}_{t_{*}},{\mathcal {P}}_{t_{*}}}\) are independently and randomly generated and cannot be compromised by the adversary. Thus, the secrecy property holds. □
The security of PCDD
The following theorem gives the security of our PCDD.
Theorem 3
The PCDD scheme described in “Additive homomorphic encryption scheme” section is semantically secure, based on the assumed intractability of the DDH assumption over \( {\mathbb {Z}}_{N^{2}}^{*}\).
Proof
The security of PCDD has been proven to be semantically secure under the DDH assumption over \( {\mathbb {Z}}_{N^{2}}^{*}\) in the standard model (Bresson et al. 2003). □
Security of TPU-based basic operation
Theorem 4
The RTG can securely generate random shares against adversary who can compromise at most \({\mathcal {P}}-1\) TPUs, assuming the semantic security of the PCDD cryptosystem.
Proof
For each TPU \(i \ (0 \leq i<{\mathcal {P}})\), only the PCDD encryption \([\!\![\mathfrak {r}^{(1)}]\!\!],\cdots,[\!\![\mathfrak {r}^{(\ell)}]\!\!]\) are sent to TPU i+1. After that, PCDD encryption [ [r] ] is sent from TPU i+1 to i. According to semantically secure of the PCDD (Theorem 3), the TPU i+1 cannot get any information from the ciphertext sent from TPU i. Even the adversary can compromise at most \({\mathcal {P}}-1\) TPUs and get the shares \(\mathfrak {r}_{i}^{(1)},\cdots, \mathfrak {r}_{i}^{(\ell)}, r_{i}\), (s)he cannot get the secret \(\mathfrak {r}^{(1)},\cdots, \mathfrak {r}^{(\ell)}, r\) due to \(\mathfrak {r}^{(1)}_{{\mathcal {P}}},\cdots, \mathfrak {r}^{(\ell)}_{{\mathcal {P}}}, r_{{\mathcal {P}}}\) are unknown to adversary according to the security of Theorem 1. □
The security proof of the secure share domain transformation in section, secure binary shares operation in section, secure integer computation, and secure FPN computation are similar to the proof of Theorem 4. The security of the above operations are based on the semantic security of the PCDD cryptosystem. Next, we will show that AHP and PIR can achieve its corresponding functionality.
Theorem 5
The AHP can securely achieve the access pattern hidden for the function input under the semantic security of the PCDD cryptosystem.
Proof
In the select share phase, all a1,⋯,aH are selected and encrypted by RU, and are sent to TPUs for processing. The adversary cannot know the plaintext of the ciphertext due to the semantic security of PCDD. Also, the shares are dynamically updated by computing \( b^{*}_{i} \leftarrow b_{i} + \delta _{1,i} + \delta _{2,i}+ \cdots +\delta _{{\mathcal {P}},i} \mod N\). As δj,i is randomly generated by TPU i and is sent from TPU j to TPU i. It is hard for the adversary to recover bi; even the adversary compromises the other \({\mathcal {P}}-1\) TPUs due to the secrecy of Theorem 2. Thus, it is still impossible for the adversary to trace the original shares with the update shares, which can achieve the access pattern hidden. □
Theorem 6
The PIR can securely achieve the private information retrieve under the semantic security of the PCDD cryptosystem.
Proof
In PIR, all a1,⋯,aH are selected and encrypted by RU, and sent to TPUs for processing. After that, [ [b∗] ] is transmitted among TPUs. As all the computations in the PIR are executed in the ciphertext domain, the adversary cannot know the plaintext of the ciphertext due to the semantic security of PCDD, which can achieve private information retrieval. □
Security of LightCom
Theorem 7
The LightCom is secure against side-channel attack if \(t_{c}+t_{p}+t_{d}< {\mathcal {P}} \cdot t_{a}\), where tc,tp and td are the runtime of secure computation GenCpt, private key update, and data share update, respectively; ta is the runtime for attacker successfully compromising the TPU enclave; \({\mathcal {P}}\) is the number of TPUs in the system.
Proof
In the data upload phase, RU’s data are randomly separated and uploaded to TPUs via a secure channel. According to Theorem 1, no useful information about the RU’s data leaked to the adversary by compromising \({\mathcal {P}}-1\) TPUs enclaves. For the long-term storage, the data shares are securely sealed in the UnS with PCDD crypto-system. With the Theorem 3, we can find the encrypted data shares are semantically secure stored in the UnS.
In the secure online computing phase, all the ciphertexts are securely loaded to the TPUs with UnSeal. Then, all the TPUs jointly achieves the secure computation with the GenCpt. During the computing phase, the system attacker can launch the following three types of attacks: 1) compromise the TPU enclave: the adversary can compromise a TPU enclave to get current data shares and private key shares with the time ta; 2) store the old private key shares: the adversary tries to recover the RU’s private key with current and old private key shares. 3) store the old data shares and try to recover the RU’s original data: the adversary tries to recover the RU’s data with current and old data shares. To prevent the first type of attack, RU separates and distributes his/her own data among \(\mathcal {P}\) TPUs. Unless the adversary can compromise all the TPU enclaves at the same time, \(\mathcal {A}\) can get nothing useful information from compromised shares according to Theorem 1. Thanks to the secrecy property of a proactive additive secret sharing scheme in Theorem 2, it is impossible for the adversary to recover the private key and RU’s data by getting \({\mathcal {P}}-1\) TPUs at each time period. As the TPU enclaves are dynamically released after the computation, the attacker needs to restart to compromise the TPU enclaves after the enclaves are built for secure computation.
Thus, the adversary fails to attack the LightCom system if the data shares are successful seals in the UnS, and all the TPU enclaves are released before the adversary compromises all the enclaves in the secure computation phase. In this case, the LightCom is secure against adversary side-channel attack if \(t_{c}+t_{p}+t_{d}< {\mathcal {P}} \cdot t_{a}\). □
Evaluations
In this section, we evaluate the performance of LightCom.
Experiment analysis
For evaluating the performance of the LightCom, we build the framework with C code under the Intel\(^{\circledR }\) Software Guard Extensions (SGX) environment as a particular case of TPUFootnote 15. The experiments are performed on a personal computer (PC) with a 3.6 GHz single-core processor and 1 GB RAM (we use the single-thread program) on a virtual machine with a Linux operation system. To test the efficiency of our LightCom, there are two types of metrics are considered, called runtime and security level (associate with PCDD parameter N). The runtime refers to the secure outsourced computation executing duration on the server or user’s side in our testbed. The security level is an indication of the security strength of a cryptographic primitive. Moreover, we use SHA-256 as the hash function H(·) in LightCom. As the communication latency among CPUs is very low (use Intel\(^{\circledR }\) UltraPath Interconnect (UPI) with 10.4 GT/s transfer speed and theoretical bandwidth is 20.8 GB/s)Footnote 16, we do not consider the communication overhead as a performance metric in our LightCom.
Basic crypto and system primitive
We first evaluate the performance of our basic operation of cryptographic primitive (PCDD cryptosystem) and basic system operations (Seal, UnSeal and SDD protocol). We first let N be 1024 bits to achieve 80-bit security (Barker et al. 2007) to test the basic crypto primitive and basic protocol. For PCDD, it takes 1.153 ms to encrypt a message (Enc), 1.171 ms for Dec, 1.309 ms to run PDec, 5.209 μs to run TDec. For the basic system operations (See Fig. 4), it takes 1.317 ms for Seal, 1.523 ms for UnSeal, and 1.512 ms for SDD (\({\mathcal {P}}=3\)). Moreover, Seal, UnSeal and SDD are affected by the PCDD parameter N and the number of TPUs \({\mathcal {P}}\) (See Fig. 4a and b respectively). From Fig. 4a and b, we can that the parameter N will significantly affect the runtime and communication overhead of the protocols.

Simulation results of Basic Protocols
Performance of TPU-based integer computation
Generally, four factors affect the performance of TPU-based integer computation: 1) the number of TPUs \(\mathcal {P}\); 2) the PCDD parameter N; 3) the bit-length of the integer ℓ; 4) the number of encrypted data H (See Fig. 5). In Fig. 5a-e, we can see that the runtime of all the protocols increase with \(\mathcal {P}\). It is because more runtime is needed, and more data in the online phase and random numbers in the offline phase are required to process with extra parties. Also, we can see that the runtime of all the TPU-based integer computations increase with the bit-length of N from Table 1. It is because the running time of the basic operations (Enc and Dec algorithms of PCDD) increases when N increases. Moreover, in Fig. 5f-k, the performance of RTG, SMM, BAdd, BExt, SEP, SC, SEQ, Min2, MinH, UNI are associated with ℓ. The computational cost of above protocols are increased with ℓ, as more computation resources are needed to process when ℓ increase. Finally, we can see that performance of APH and PIR are increased with H in Fig. 5l. It is because more numbers of PCDD ciphertexts cost more energy with the homomorphic and module exponential operations.

Simulation results of LightCom
Performance of TPU-based FPN computation
For the basic TPU-based FPN computation, four factors affect the performance of LightCom: 1) the number of TPUs; 2) the PCDD parameter N; 3) the bit-length of the integer ℓ; 4) the number of encrypted data H. The runtime trends of FPN computation protocols (e.g. FC, FEQ, FM, FMM, FMin2, FMinH) are similar to the trends of corresponding secure integer computation (e.g. SC, SEQ, SM, SMM, Min2, MinH), as the runtime of FPN computation is equal to the runtime of corresponding secure integer computation add the runtime of UNI.
Theoretical analysis
Let us assume that one regular exponentiation operation with an exponent of ∥N∥ requires 1.5 ∥N∥ multiplications (Knuth 2014). For PCDD, it takes 3∥N∥ multiplications for Enc, 1.5∥N∥ multiplications for Dec, 1.5∥N∥ multiplications for PDec, \(\mathcal {P}\) multiplications for TDec, 1.5∥N∥ multiplications for CR. For the basic operation of LightCom, it takes \(1.5 {\mathcal {P}} \|N\|\) multiplications to run SDD, 3∥N∥+thash multiplications for Seal, \(1.5{\mathcal {P}}\|N\|+t_{hash}\) multiplications for UnSeal, \({\mathcal {O}} ((\ell +{\mathcal {P}})\|N\|)\) multiplications for RTG, \({\mathcal {O}} ({\mathcal {P}}\|N\|)\) multiplications for B2I, I2B. For the integer and binary protocol in LightCom, it takes \({\mathcal {O}} ({\mathcal {P}}\|N\|)\) multiplications for offline phase of SBM and SM, \({\mathcal {O}} (\ell {\mathcal {P}}\|N\|)\) multiplications for offline phase of BAdd, BExt, SC, SEQ, Min2, \({\mathcal {O}} (\ell {\mathcal {P}}\|N\|)\) multiplications for both offline and online phase of SEP, \({\mathcal {O}} (H {\mathcal {P}}\|N\|)\) multiplications for offline phase of APH and PIR, \({\mathcal {O}} (\lceil \log _{2}H \rceil \cdot \ell {\mathcal {P}}\|N\|)\) multiplications for offline phase of MinH. For the FPN computation in LightCom, it takes \({\mathcal {O}} (H \ell {\mathcal {P}}\|N\|)\) multiplications for offline phase UNI and FAdd, \({\mathcal {O}} (\ell {\mathcal {P}}\|N\|)\) multiplications for offline phase FM, FMM, FC, FEQ, FMin2, and \({\mathcal {O}} (\lceil \log _{2}H \rceil \cdot \ell {\mathcal {P}}\|N\|)\) multiplications for offline phase of FMinH. All the above protocols only need \({\mathcal {O}}(1)\) multiplications in online phase, which is greatly fit for fast processing.
Related work
Homomorphic Encryption. Homomorphic encryption allows third-party to do the computation on the ciphertext, which reflected on the plaintext, is considered as the best solution to achieve the secure outsourced computation. Gentry proposed the first construction of fully homomorphic encryption in 2009 under the ideal lattices, which permits the evaluation of arbitrary circuits over the plaintext (Gentry and et al. 2009). Later, some of the new hard problems (such as Learning With Errors (LWE) (Brakerski and Vaikuntanathan 2014), Ring-LWE (Brakerski et al. 2014)) are used to construct the FHE which can greatly reduce the storage overhead and increase the performance of the homomorphic operations (Chillotti et al. 2016; Liu et al. 2020). However, the current FHE solutions and libraries are still not practical enough for the real real-world scenarios (Doröz et al. 2015; Liu et al. 2017). Somewhat homomorphic encryption (Damgård et al. 2012; Fan and Vercauteren 2012) can allow semi-honest third-party to achieve the arbitrary circuits with limited depth. The limited times of homomorphic operations restrict the usage scope of the application. Semi-homomorphic encryption (SHE) can only support additive (Paillier 1999) (or multiplicative Gamal (1985)) homomorphic operation. However, with the help of the extra semi-honest computation-aid server, a new computation framework can be constructed to achieve commonly-used secure rational number computation (Liu et al. 2018a), secure multiple keys computation (Peter et al. 2013), and floating-point number computation (Liu et al. 2016b). The new framework can greatly balance the security and efficiency concerns; however, the extra server will still complex the system, which brings more risk of information leakage.
Secret Sharing-based Computation. The user’s data in secret sharing-based (SS-based) computation are separated into multiple shares with the secret sharing technique, and each share is located in one server to guarantee security. Multiple parties can work jointly together to securely achieve a computation without leaking the original data to the adversary. Different from the heavyweight homomorphic operation, the SS-based computation (Cramer et al. 2000; Chen and Cramer 2006; Chida et al. 2018) can achieve the lightweight computation. Despite the theoretical construction, many real-word computation are constructed for practical usage, such as SS-based set intersection (Dong et al. 2013), top-k computation (Burkhart and Dimitropoulos 2010) and k-means (Liu et al. 2020). These basic computations can be used to solve data security problem in data mining technique, such as deep learning (Huang et al. 2019). Emekçi et al. (Emekçi et al. 2007) proposed a secure ID3 algorithm to construct a decision tree in a privacy-preserving manner. Ma et al. (Ma et al. 2019) constructed a lightweight privacy-preserving adaptive boosting (AdaBoost) for the face recognition. The new secure natural exponential and secure natural logarithm which can securely achieve the corresponding computation to balance accuracy and efficiency. Although many of the privacy-preserving data mining techniques with secret sharing are constructed (Ge et al. 2010; Gheid and Challal 2016), the SS-based computation still needs to build a secure channel among these parties. Moreover, the high communication rounds among the computation parties still become an obstacle for a large-scale application.
Intel\(^{\circledR }\)Software Guard Extensions. Intel\(^{\circledR }\) SGX is a kind of TEE which provides strong hardware-enforced confidentiality and integrity guarantees and protects an application form the host OS, hypervisor, BIOS, and other software. Although an increasing number of real-world industry applications are securely executed in the untrusted remote platforms equipped with SGX, the SGX still faces the side-channel attack to expose the information during the computation. Götzfried et al. (2017) proposed a new attack called root-level cache-timing attacks which can obtain secret information from an Intel\(^{\circledR }\) SGX enclave. Lee et al. (2017) gave a new side-channel attack cannled branch shadowing which reveals fine-grained control flows in a SGX enclave. Van Bulck et al. (2017) constructed two novel attack vectors that infer enclaved memory accesses. Chen et al. (2018) presented a new attack call SGXPECTRE that can learn secrets inside the enclave memory or its internal registers. Currently, three types of solutions are used to protect the side-channel attack: hardware method (Domnitser et al. 2012; Costan et al. 2016), system method (Liu et al. 2016c; Zhou et al. 2016), and application method (Coppens et al. 2009; Shih et al. 2017). These methods can only guarantee some dimension of protection, and cannot be used for all-directional protection even against the unknown side-channel attack. We list all the current main methods in Table 2 for detailed comparison.
Conclusion
In this paper, we proposed LightCom, a framework for practical privacy-preserving outsourced computation framework, which allowed a user to outsource encrypted data to a single cloud service provider for secure data storage and process. We designed two types of outsourced computation toolkits, which can securely guarantee the achieve secure integer computation and floating-point computation against side-channel attack. The utility and performance of our LightCom framework were then demonstrated using simulations. Compared with the existing secure outsourced computation framework, our LightCom takes fast, scalable, and secure outsourced data processing into account.
As a future research effort, we plan to apply our LightCom in specific applications, such as the e-health cloud system. It allows us to refine the framework to handle more complex real-world computations.
Availability of data and materials
All the data used in the paper are randomly constructed (integer randomly selected from \(\mathbb {Z}_{N}\) and floating-point number are selected from \(\mathbb {Z}^{2}_{N}\)). Submission of a manuscript to a cybersecurity journal implies that materials described in the manuscript, including all relevant raw data, will be freely available to any scientist wishing to use them for non-commercial purposes, without breaching participant confidentiality.
Notes
See the algorithm Seal and UnSeal in “Secure TPU-based data seal & UnSeal” section.
Note that \({\mathcal {P}} \geq 3\) TPUs are required in LightCom for the security consideration.
The construction of General Secure Function Computation Algorithm (GenCpt) can be found in “General secure function computation algorithm (GenCpt)” section.
Data share xj,t,i is for TPU enclave i for data j of function computation step-t.
As offline stage of the secure computations needs to do TPU enclave initialization, we just omit the description in the rest of the section.
The input data x1,i,⋯,xv,i,, public key pk, private key shares ski, and the program \({\mathcal {C}}_{i}\) are loaded in the step of (3-I) of both “The LightCom design method for the single functions” and “The LightCom Design for Combination of the Functions” sections.
β is a small positive number which satisfies gcd(β,N)=1.
Currently, Intel SGX is considered as the most practical and typical TEE. Thus, we use SGX as the TPU for testing the LightCom. Note that the LightCom is designed as a generic privacy computation framework and can be fit for any trusted execution environment. Any types of TPU can be used in the LightCom.
References
Ali, M, Khan SU, Vasilakos AV (2015) Security in cloud computing: Opportunities and challenges. Inf Sci 305:357–383.
Barker, E, Barker W, Burr W, Polk W, Smid M (2007) NIST special publication 800-57. NIST Spec Publ 800(57):1–142.
Bendlin, R, Damgård I, Orlandi C, Zakarias S (2011) Semi-homomorphic encryption and multiparty computation In: Annual International Conference on the Theory and Applications of Cryptographic Techniques, 169–188.. Springer. https://doi.org/10.1007/978-3-642-20465-4_11.
Brakerski, Z, Gentry C, Vaikuntanathan V (2014) (leveled) fully homomorphic encryption without bootstrapping. ACM Trans Comput Theory (TOCT) 6(3):13.
Brakerski, Z, Vaikuntanathan V (2014) Efficient fully homomorphic encryption from (standard) lwe. SIAM J Comput 43(2):831–871.
Bresson, E, Catalano D, Pointcheval D (2003) A simple public-key cryptosystem with a double trapdoor decryption mechanism and its applications In: Advances in Cryptology - ASIACRYPT 2003, 9th International Conference on the Theory and Application of Cryptology and Information Security, Taipei, Taiwan, November 30 - December 4, 2003, Proceedings, 37–54. https://doi.org/10.1007/978-3-540-40061-5_3.
Burkhart, M, Dimitropoulos X (2010) Fast privacy-preserving top-k queries using secret sharing In: 2010 Proceedings of 19th International Conference on Computer Communications and Networks, 1–7.. IEEE. https://doi.org/10.1109/icccn.2010.5560086.
Challa, S, Das AK, Gope P, Kumar N, Wu F, Vasilakos AV (2020) Design and analysis of authenticated key agreement scheme in cloud-assisted cyber–physical systems. Future Gener Comput Syst 108:1267–1286.
Chandra, S, Karande V, Lin Z, Khan L, Kantarcioglu M, Thuraisingham B (2017) Securing data analytics on sgx with randomization In: European Symposium on Research in Computer Security, 352–369.. Springer. https://doi.org/10.1007/978-3-319-66402-6_21.
Chen, G, Chen S, Xiao Y, Zhang Y, Lin Z, Lai TH (2018) Sgxpectre attacks: Leaking enclave secrets via speculative execution. arXiv preprint arXiv:1802.09085.
Chen, H, Cramer R (2006) Algebraic geometric secret sharing schemes and secure multi-party computations over small fields In: Annual International Cryptology Conference, 521–536.. Springer.
Chida, K, Genkin D, Hamada K, Ikarashi D, Kikuchi R, Lindell Y, Nof A (2018) Fast large-scale honest-majority mpc for malicious adversaries In: Annual International Cryptology Conference, 34–64.. Springer. https://doi.org/10.1007/978-3-319-96878-0_2.
Chillotti, I, Gama N, Georgieva M, Izabachene M (2016) Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds In: International Conference on the Theory and Application of Cryptology and Information Security, 3–33.. Springer. https://doi.org/10.1007/978-3-662-53887-6_1.
Consortium, U, et al. (1997) The Unicode Standard, Version 2.0. Addison-Wesley Longman Publishing Co., Inc., Boston.
Coppens, B, Verbauwhede I, De Bosschere K, De Sutter B (2009) Practical mitigations for timing-based side-channel attacks on modern x86 processors In: 2009 30th IEEE Symposium on Security and Privacy, 45–60.. IEEE. https://doi.org/10.1109/sp.2009.19.
Costan, V, Lebedev I, Devadas S (2016) Sanctum: Minimal hardware extensions for strong software isolation In: 25th {USENIX} Security Symposium ({USENIX} Security 16), 857–874.. USENIX Association, Austin.
Cramer, R, Damgård I, Maurer U (2000) General secure multi-party computation from any linear secret-sharing scheme In: International Conference on the Theory and Applications of Cryptographic Techniques, 316–334.. Springer. https://doi.org/10.1007/3-540-45539-6_22.
Damgård, I, Pastro V, Smart N, Zakarias S (2012) Multiparty computation from somewhat homomorphic encryption In: Annual Cryptology Conference, 643–662.. Springer. https://doi.org/10.1007/978-3-642-32009-5_38.
Dimitrov, DV (2016) Medical internet of things and big data in healthcare. Healthc Inf Res 22(3):156–163.
Domnitser, L, Jaleel A, Loew J, Abu-Ghazaleh N, Ponomarev D (2012) Non-monopolizable caches: Low-complexity mitigation of cache side channel attacks. ACM Trans Archit Code Optim (TACO) 8(4):35.
Dong, C, Chen L, Wen Z (2013) When private set intersection meets big data: an efficient and scalable protocol In: Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, 789–800.. ACM. https://doi.org/10.1145/2508859.2516701.
Doröz, Y, Öztürk E, Sunar B (2015) Accelerating fully homomorphic encryption in hardware. IEEE Trans Comput 64(6):1509–1521.
Emekçi, F, Sahin OD, Agrawal D, El Abbadi A (2007) Privacy preserving decision tree learning over multiple parties. Data Knowl Eng 63(2):348–361.
Fan, J, Vercauteren F (2012) Somewhat practical fully homomorphic encryption. IACR Cryptology ePrint Archive 2012:144.
Farokhi, F, Shames I, Batterham N (2016) Secure and private cloud-based control using semi-homomorphic encryption. IFAC-PapersOnLine 49(22):163–168.
Gamal, TE (1985) A public key cryptosystem and a signature scheme based on discrete logarithms, 469–472.
Ge, X, Yan L, Zhu J, Shi W (2010) Privacy-preserving distributed association rule mining based on the secret sharing technique In: The 2nd International Conference on Software Engineering and Data Mining, 345–350.. IEEE, Chengdu.
Gentry, C, et al. (2009) Fully homomorphic encryption using ideal lattices In: Stoc, 169–178.
Gheid, Z, Challal Y (2016) Efficient and privacy-preserving k-means clustering for big data mining In: 2016 IEEE Trustcom/BigDataSE/ISPA, 791–798.. IEEE. https://doi.org/10.1109/trustcom.2016.0140.
Götzfried, J, Eckert M, Schinzel S, Müller T (2017) Cache attacks on intel sgx In: Proceedings of the 10th European Workshop on Systems Security (EuroSec’17).. Association for Computing Machin, New York. Article 2, pp. 1–6.
Huang, K, Liu X, Fu S, Guo D, Xu M (2019) A lightweight privacy-preserving cnn feature extraction framework for mobile sensing. IEEE Trans Dependable Secure Comput. https://doi.org/10.1109/tdsc.2019.2913362.
Knuth, DE (2014) Art of Computer Programming, Volume 2: Seminumerical Algorithms. Addison-Wesley Professional, Boston.
Küçük, KA, Paverd A, Martin A, Asokan N, Simpson A, Ankele R (2016) Exploring the use of intel sgx for secure many-party applications In: Proceedings of the 1st Workshop on System Software for Trusted Execution, 5.. ACM. https://doi.org/10.1145/3007788.3007793.
Lee, S, Shih M-W, Gera P, Kim T, Kim H, Peinado M (2017) Inferring fine-grained control flow inside {SGX} enclaves with branch shadowing In: 26th {USENIX} Security Symposium ({USENIX} Security 17), 557–574.. USENIX Association, Vancouver.
Liu, X, Choo K-KR, Deng RH, Lu R, Weng J (2018a) Efficient and privacy-preserving outsourced calculation of rational numbers. IEEE Trans Dependable Secure Comput 15(1):27–39.
Liu, X, Deng RH, Choo K-KR, Weng J (2016a) An efficient privacy-preserving outsourced calculation toolkit with multiple keys. IEEE Trans Inf Forensic Secur 11(11):2401–2414.
Liu, X, Deng R, Choo K-KR, Yang Y (2017) Privacy-preserving outsourced clinical decision support system in the cloud. IEEE Trans Serv Comput. https://doi.org/10.1109/tsc.2017.2773604.
Liu, X, Deng R, Choo K-KR, Yang Y, Pang H (2018b) Privacy-preserving outsourced calculation toolkit in the cloud. IEEE Trans Dependable Secure Comput. https://doi.org/10.1109/tdsc.2018.2816656.
Liu, X, Deng R, Choo K-KR, Yang Y, Pang H (2020) Privacy-preserving outsourced calculation toolkit in the cloud. IEEE Trans Dependable Secure Comput 17(5):898–911.
Liu, X, Deng RH, Ding W, Lu R, Qin B (2016b) Privacy-preserving outsourced calculation on floating point numbers. IEEE Trans Inf Forensic Secur 11(11):2513–2527.
Liu, F, Ge Q, Yarom Y, Mckeen F, Rozas C, Heiser G, Lee RB (2016c) Catalyst: Defeating last-level cache side channel attacks in cloud computing In: 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), 406–418.. IEEE. https://doi.org/10.1109/hpca.2016.7446082.
Liu, Y, Ma Z, Yan Z, Wang Z, Liu X, Ma J (2020) Privacy-preserving federated k-means for proactive caching in next generation cellular networks. Inf Sci. https://doi.org/10.1016/j.ins.2020.02.042.
Ma, Z, Liu Y, Liu X, Ma J, Ren K, IEEE Internet Things J (2019) Lightweight privacy-preserving ensemble classification for face recognition:1–1. https://doi.org/10.1109/JIOT.2019.2905555.
Ma, Z, Ma J, Miao Y, Choo K-KR, Liu X, Wang X, Yang T (2020) Pmkt: Privacy-preserving multi-party knowledge transfer for financial market forecasting. Futur Gener Comput Syst. https://doi.org/10.1016/j.future.2020.01.007.
Naehrig, M, Lauter K, Vaikuntanathan V (2011) Can homomorphic encryption be practical? In: Proceedings of the 3rd ACM Workshop on Cloud Computing Security Workshop, 113–124.. ACM. https://doi.org/10.1145/2046660.2046682.
Paillier, P (1999) Public-key cryptosystems based on composite degree residuosity classes In: Advances in cryptologyEUROCRYPT99, 223–238.. Springer. https://doi.org/10.1007/3-540-48910-x_16.
Peter, A, Tews E, Katzenbeisser S (2013) Efficiently outsourcing multiparty computation under multiple keys. IEEE Trans Inf Forensic Secur 8(12):2046–2058.
Samanthula, BK, Elmehdwi Y, Jiang W (2014) K-nearest neighbor classification over semantically secure encrypted relational data. IEEE Trans Knowl Data Eng 27(5):1261–1273.
Shaon, F, Kantarcioglu M, Lin Z, Khan L (2017) Sgx-bigmatrix: A practical encrypted data analytic framework with trusted processors In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 1211–1228.. ACM. https://doi.org/10.1145/3133956.3134095.
Shih, M-W, Lee S, Kim T, Peinado M (2017) T-sgx: Eradicating controlled-channel attacks against enclave programs In: NDSS. https://doi.org/10.14722/ndss.2017.23193.
Van Bulck, J, Weichbrodt N, Kapitza R, Piessens F, Strackx R (2017) Telling your secrets without page faults: Stealthy page table-based attacks on enclaved execution In: 26th {USENIX} Security Symposium ({USENIX} Security 17), 1041–1056.. USENIX Association, Vancouver.
Van Dijk, M, Gentry C, Halevi S, Vaikuntanathan V (2010) Fully homomorphic encryption over the integers In: Advances in Cryptology — EUROCRYPT 2010. EUROCRYPT 2010. Lecture Notes in Computer Science, vol 6110, 24–43.. Springer, Berlin.
Wazid, M, Das AK, Bhat V, Vasilakos AV (2020) Lam-ciot: Lightweight authentication mechanism in cloud-based iot environment. J Netw Comput Appl 150:102496.
Wei, L, Zhu H, Cao Z, Dong X, Jia W, Chen Y, Vasilakos AV (2014) Security and privacy for storage and computation in cloud computing. Inf Sci 258:371–386.
Xu, S, Ning J, Li Y, Zhang Y, Xu G, Huang X, Deng R (2020a) Match in my way: Fine-grained bilateral access control for secure cloud-fog computing. IEEE Trans Dependable Secure Comput. https://doi.org/10.1109/tdsc.2020.3001557.
Xu, S, Yang G, Mu Y, Deng R (2018) Secure fine-grained access control and data sharing for dynamic groups in the cloud. IEEE Trans Inf Forensic Secur 13(8):2101–2113.
Xu, S, Yuan J, Xu G, Li Y, Liu X, Zhang Y, Ying Z (2020b) Match in my way: Fine-grained bilateral access control for secure cloud-fog computing. Inf Sci. https://doi.org/10.1109/tdsc.2020.3001557.
Zhou, Z, Reiter MK, Zhang Y (2016) A software approach to defeating side channels in last-level caches In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 871–882.. ACM. https://doi.org/10.1145/2976749.2978324.
Acknowledgements
We thank the editor-in-chief, associate editor, and the reviewers for their valuable comments for us to improve the paper. This research is supported in part by the AXA Research Fund, National Natural Science Foundation of China under Grant Nos.61702105, No.61872091, and the Cloud Technology Endowed Professorship from the the 80/20 Foundation.
Author information
Authors and Affiliations
Contributions
Authors’ contributions
Ximeng Liu — Writing and original draft preparation. Robert H. Deng — Supervision. Pengfei Wu — Experiment. Yang Yang; writing-Review and editing. The author(s) read and approved the final manuscript.
Authors’ information
Ximeng Liu received the B.Sc. degree in electronic engineering from Xidian University, Xi’an, China, in 2010 and the Ph.D. degree in Cryptography from Xidian University, China, in 2015. Now he is the full professor in the College of Mathematics and Computer Science, Fuzhou University. Also, he was a research fellow at the School of Information System, Singapore Management University, Singapore. He has published more than 200 papers on the topics of cloud security and big data security-including papers in IEEE Transactions on Computers, IEEE Transactions on Industrial Informatics, IEEE Transactions on Dependable and Secure Computing, IEEE Transactions on Service Computing, IEEE Internet of Things Journal, and so on. He awards "Minjiang Scholars" Distinguished Professor, "Qishan Scholars" in Fuzhou University, and ACM SIGSAC China Rising Star Award (2018). His research interests include cloud security, applied cryptography and big data security. He is a member of the IEEE, ACM, CCF.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing financial interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1
Supplementary materials.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, X., Deng, R.H., Wu, P. et al. Lightning-fast and privacy-preserving outsourced computation in the cloud. Cybersecur 3, 17 (2020). https://doi.org/10.1186/s42400-020-00057-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42400-020-00057-3